
- これだけ読めば大丈夫!1ヶ月ニュース要約
- 新しいLLM&チャットAI
- Meta、オープンソースのLLM「Llama3」を発表 派生利用が可能
- rinna、Llama 3 8Bに対して日本語データで事前学習を行った「Llama 3 Youko 8B」を開発
- Mistral AIは、新しいAIモデル「Mixtral 8x22B」を発表 スパース混合専門家(SMoE)モデルで高速かつ高機能
- 東京工業大学ら、スーパーコンピュータ「富岳」で学習した大規模言語モデル「Fugaku-LLM」を公開
- Stability AI, マルチモーダルなチャットボット「Stable Assistant」のベータ版を公開
- 8Bパラメータのマルチモーダルモデル「Idefics2」Hugging FaceがGoogleとMistralAIと共同で開発
- RekaAI、マルチモーダルモデル「Reka Core」を発表 Snowflake、Oracleなどと提携
- 小規模なモバイル向け言語モデル
- 新サービス
- 画像・動画生成AI
- ディープラーニング新技術
- LLM新技術
- LLMの評価
- AIの活用
- OpenAIニュース
- 新聞社とLLM
- ニュース
- 国内ニュース
- ロボット&デバイス
これだけ読めば大丈夫!1ヶ月ニュース要約
- Meta、オープンソースのLLM「Llama3」を発表 派生利用が可能
- MetaのLlama 3は、オープンアクセスのLlamaファミリーの最新バージョンで、Hugging Faceで公開されているよ
- Llama 3は、8B(効率的な開発とデプロイメント用)と70B(大規模AIアプリケーション用)の2つのサイズで提供されており、それぞれに基本版と指示調整版があるよ
- 新たなLlama Guard 2もリリースされており、Llama 3 8Bでファインチューニングされた安全対策モデルだよ
- 新しいGrouped-Query Attention(GQA)技術を使用しており、長いコンテキストでの効率的な表現が可能だよ
- Llama 3のライセンスは、再配布、ファインチューニング、派生作品の作成を許可しているけど、「Llama 3」という名前の明記や、派生作品に「Built with Meta Llama 3」と記述することが必要だよ
- HuggingFaceのTRLを使って、Llama 3を消費者向けGPUでファインチューニングする方法も紹介されており、効率的なトレーニングが可能だよ
- さっそくrinnaがLlama3 8Bに対して日本語データで事前学習したモデルを発表しているよ
- Mistral AIは、新しいAIモデル「Mixtral 8x22B」を発表 スパース混合専門家(SMoE)モデルで高速かつ高機能
- 141Bのパラメーターのうち39Bだけが活性化されるスパース混合専門家(SMoE)モデルだよ
- 英語、フランス語、イタリア語、ドイツ語、スペイン語に堪能であり、数学とプログラミングの能力が非常に高いよ
- Apache 2.0ライセンスの下で公開され、誰でもどこでも制限なく使用できるよ
- スパース混合専門家(SMoE)モデルとは、ネットワーク全体が一度にすべてのパラメータを使用するのではなく、特定のタスクや入力に応じて「専門家」と呼ばれる小さなネットワークのサブセットのみを活性化するよ。これによりリソースの使用を最適化できるよ
- 東京工業大学ら、スーパーコンピュータ「富岳」で学習した大規模言語モデル「Fugaku-LLM」を公開
- 東京工業大学、東北大学、富士通、理化学研究所、名古屋大学、サイバーエージェント、Kotoba Technologies の研究チームが開発したよ
- 「富岳」の性能を最大限に活用した分散並列学習を実現し、既存技術に比べて演算速度を6倍、通信速度を3倍に高速化したよ
- 130億パラメータのモデルで、日本語性能に優れているよ
- 8Bパラメータのマルチモーダルモデル「Idefics2」Hugging FaceがGoogleとMistralAIと共同で開発
- 事前学習後にさまざまなタスクに対してファインチューニングできるよう、Transformers ライブラリに統合されているよ
- コミュニティ向けにオープンソースデータセット「The Cauldron」を公開しているよ
- Microsoftの小規模で高性能な言語モデル「Phi-3」
- 38億個のパラメータを持ち、そのサイズの2倍のモデルよりも優れた性能を発揮するよ
- 70億パラメータを持つ「Phi-3-small」と、140億パラメータを持つ「Phi-3-medium」も近日中に発表される予定だよ
- Apple、オープンソースのLLM「OpenELM」発表 パラメータを効率的に配分することで高精度を実現
- MLXライブラリを使ってAppleデバイス上での推論とファインチューニングが可能だよ
- トランスフォーマーモデルのレイヤーごとに効率的にパラメータを割り当てる「レイヤー毎のスケーリング戦略」を採用しているよ
- パラメータ数を約10億個に抑えつつ、既存の言語モデルOLMoに比べて2.36%の精度向上を実現しているよ
- MLXは、Appleのデバイスでモデルを推論およびファインチューニングするために使用されるライブラリだよ
- OpenAI、ChatGPT plusでチャットの内容を記憶させる機能「Memory」正式提供
- LLMで開発プロセス全体をサポートする「GitHub Copilot Workspace」
- 自然言語を用いてIssueを定義すると、課題の定義、仕様の作成、コード実装、テスト実行まで、開発プロセス全体をAIがやってくれるよ
- AWSの生成AIアシスタント「Amazon Q」一般提供開始
- Microsoftの「Copilot」のような、Chat AIアシスタントだよ
- ソフトウェア開発や社内データの参照などに特化しているよ
- 料金は1ユーザー当たり20ドルからで、現在は英語版のみが提供されているよ
- 自然言語で業務アプリのニーズを記述するだけで、求める業務を遂行するアプリを生成できる機能「Amazon Q Apps」もあるよ
- Anthropic、ClaudeのTeamプランとiOSアプリの提供を開始
- Google、日本におけるGeminiのAndroid&iOSアプリの提供開始
- エンドルフィン社の「ピュアモデルAI」は特定の漫画家の絵柄だけを学習させるAI
- エンドルフィン社は韓国発祥のデジタル漫画「ウェブトゥーン」制作会社だよ
- Stable Diffusionをベースにしているよ
- 追加学習モデル『LoRA』を使っているだけでは、という指摘もあったけど、画像の生成までに独自のプロセスを踏んでいるらしいよ
- 特許出願中なので、詳しい説明ができないんだって。気になるね!
- 「Stable DiffusionとCLIP(画像をテキストとして認識したり、テキストから生成画像に影響を与えるエンコーダー機能)等を使っているって
- 少なくとも50枚の画像が必要で、より精密なファインチューニングを行う場合には追加の画像が必要になるよ
- 拡散ベースの生成モデルにおける画像や動画の一貫性を向上させる新しい手法「StoryDiffusion」
- 「一貫性を備えた自己アテンション」と呼ばれる新しい自己アテンションの計算方法を導入したよ
- 複雑な詳細を含む画像を一貫して生成することできるようになったよ
- また、「Semantic Motion Predictor」と呼ばれる新たなモジュールを提案しているよ
- このモジュールによって、2つの入力画像の間をスムーズに繋いで一貫した被写体をもつ動画にできるよ
- Microsoft、一枚の静止画と音声クリップから、リアルタイムで話す顔のビデオを生成する「VASA-1」
- 一枚の静止画と音声クリップから、リアルタイムで話す顔のビデオを生成できるよ
- 音声に完璧に同期する唇の動きと、自然な頭の動きを含む顔のニュアンスを捉えることができるよ
- 新しいニューラルネットワークアーキテクチャ「Kolmogorov-Arnold Networks(KAN)」各エッジに可変の活性化関数を持つ
- 従来のMulti-Layer Perceptrons (MLP)では、各ノードに固定の活性化関数が使用されていたよ
- Kolmogorov-Arnold Networks (KAN)では、各エッジ(重み)に可変の活性化関数を持つよ
- 線形の重みパラメータを一切持たず、代わりにスプラインで表現された1変数の関数を重みパラメータとして使用するよ
- データフィッティングや偏微分方程式の解法において、KANはMLPよりはるかに小さなネットワークサイズで同等以上の精度を達成できるよ
- NTT、深層学習で過去の学習過程を新しいモデルに再利用する「学習転移」技術発表
- 「学習転移」技術は過去の学習過程を新しいモデルに再利用するよ
- 大規模な基盤モデルを用途に合わせてチューニングする際の再学習コストを大幅に削減できるよ
- 学習転移を2つのパラメータ初期値間の最適な置換変換を求める最適化問題として定式化したよ
- 未知のターゲットの学習過程を勾配で近似し、部分的な転移と線形最適化を交互に行うよ
- In-Context Learning
- プロンプト内で与えられた情報と、学習フェーズで取り込んだ広範なデータセットから得た情報を組み合わせて回答を生成するよ
- 新たな学習フェーズを設けないので、柔軟な応用が可能だよ
- 文脈の中からタスクの解決に必要な情報やパターンを抽出し、それを基にして新しい問いに答えるよ
- 数百~数千の事例を利用した場合のLLMの性能調査 Many-Shot In-Context Learning
- プロンプト内で少ない事例を与えた場合でもin-context学習できるけど、数百~数千の事例(many-shot)を利用した場合にどうなるか調べたよ
- 数百〜数千の事例を集めるのが大変だよ
- かわりにモデル自身が生成した論理的な推論過程を利用する「Reinforced ICL」と事例そのものは与えない「Unsupervised ICL」という手法を使ったよ
- 大規模なコンテキストを用いたin-context learningの振る舞い調査
- 最近の言語モデルは一度に入力できるコンテキストの長さが大幅に増加しており、モデルへ与えることができるデモンストレーション(入力と出力のペア)の数は、トレーニングデータセットの大きさに近づきつつあるよ
- 大規模なコンテキストを用いたin-context learningの振る舞いを多様なデータセットとモデルについて調査したよ
- 長いコンテキストを利用すると多数の類似した例を参照できて性能が向上するけど、実際のタスク学習の向上には限界があるよ
- LLMを複数のトークンを同時に予測するように訓練することで高速推論が可能に
- 大規模言語モデルであるGPTやLlamaは、次のトークンを予測するロスを用いて訓練されているよ
- 一度に複数のトークンを同時に予測するように訓練することで、より効率的にサンプルを利用できることがわかったよ
- 「トークン予測」とは、言語モデルがある単語の次に何が来るかを予測するプロセスで、「トークン」とは、単語、句読点、空白などの言語の基本的な構成要素のことだよ
- 訓練中、各位置でモデルに対して、共有されたモデルの本体の上で動作するn個の独立した出力ヘッドを使用して、各ヘッドは独立して異なるトークンを予測するよう求めるよ
- LLMのコード生成機能を計測するベンチマーク「LiveCodeBench」
- UC Berkeley、MIT、Cornellの研究者によって開発された新しいベンチマークだよ
- LeetCode、AtCoder、CodeForcesといったさまざまなコーディングコンテストプラットフォームから蓄積されたコーディング問題を利用しているよ
- ヘルスケア分野におけるLLMの性能を評価する「The Open Medical-LLM Leaderboard」
- MedQA、PubMedQA、MedMCQAなどの様々な医療分野のデータセットを使って、LLMの医療知識とQA能力を包括的に評価するよ
- 主な評価指標は正答率(Accuracy)だよ
- LLMの小学校レベルの算術問題に対するパフォーマンス調査
- LLMの数学的推論能力を評価するためのGSM1k(Grade School Math 1000)というベンチマークを開発したよ
- LLMの数学能力が高まっていると言われているけど、ベンチマークの質問に酷似したデータが訓練データに漏れる「データセットの汚染」が起きている恐れがあるよ
- Phiやミストラルなどのモデルは、ほとんどすべてのモデルサイズで過学習の傾向が示されたよ
- Gemini、GPT、Claudeなどの最先端のモデルは、過剰適合の兆候がほとんど見られなかったよ
- 多くのモデルが既存のベンチマークGSM8kの問題を部分的に記憶していることが示唆されたよ
- Stack OverflowとOpenAIが新たなAPI連携を発表
- OpenAIはStack OverflowのOverflowAPIを活用し、ユーザーや開発者にとってより良いAIモデルの構築を行うよ
- ChatGPT上でStack Overflowのコミュニティから提供される信頼性の高いテクニカルな知識やコードを表示するよ
- Stack Overflowは、OpenAIのモデルを自社のOverflowAIの開発に活用し、内部テストの結果をOpenAIにフィードバックするよ
- 新聞社とLLM
- 日本経済新聞は40年分の記事を学習させた経済特化AI「NIKKEI Language Model」を開発したよ。まだ日経新聞の執筆には使っていないよ。
- OpenAIとパートナーシップを締結した新聞社があるよ
- イギリスのフィナンシャル・タイムズ
- ドイツのアクセル・シュプリンガー
- フランスのル・モンド
- スペインのプリサ・メディア
- OpenAIやMicrosoftはアメリカの新聞社から著作権侵害で訴えられているよ
- ビッグテックの決算が発表されたよ
- Microsoft, Googleはクラウドが校長で2桁台の増収増益だよ
- Appleは減収減益だけど、過去最高の自社株買いをしたよ
- Appleは次のテックイベントでAIを搭載したサービスやデバイスの提供を予定していると噂されているよ
- Microsoftがアジアの生成AI・クラウドに大型投資
- 日本に29億ドル
- UAEに15億ドル
- インドネシアに17億ドル
- マレーシアに22億ドル
- Boston Dynamicsは、新しい全電動版の人型ロボットAtlasを発表
- Boston Dynamicsは四足歩行の(ちょっと気持ち悪い)ロボットSpotが有名な会社だよ
- 人型ロボットAtlasはこれまで油圧式だったけど、今回全電動版が発表されたよ
- Orbit™という新しいソフトウェアも導入されているよ
- 日常会話を録音して要約できるペンダント型AIガジェット「Pendant」
- Pendantは、日常会話を録音してLimitlessに送信し、要約できるペンダント型デバイスだよ
- Limitlessはオンライン会議向けのAIツールで、会話内容の文字起こしや要約が可能です。ツールはWindows、macOS、ウェブアプリに対応しており、ZoomやSlackなど多様なオンライン会議ツールと連携可能だよ
- 価格は99ドルで、2024年第4四半期に出荷が開始される予定だよ
新しいLLM&チャットAI
Meta、オープンソースのLLM「Llama3」を発表 派生利用が可能

Meta社が開発した次世代の大規模言語モデル「Llama 3」が公開されました。Llama 3には以下の特徴があります。
1. モデルサイズ: 8B (小規模)と70B (大規模)の2種類が用意されています。両モデルともに、ベースモデルと命令チューニングされたバージョンが提供されています。また、これらに加えて、Llama 3 8Bをベースにしたセーフティ重視のモデル「Llama Guard 2」も公開されました。
2. トークン数の拡張: Llama 2の32,000トークンから、Llama 3では128,256トークンへと拡張されました。これにより、入出力の効率が向上し、多言語性能も強化されています。
3. アーキテクチャの改善: 8Bモデルでは、メモリ効率の良い「Grouped-Query Attention」が採用されました。また、全体的な精度向上のため、大量のデータ(15トリリオントークン以上)を用いてさらなる学習が行われました。
4. 使いやすさの向上: Hugging Faceとの密接な連携により、この新しいLlama 3モデルをTransformersライブラリから簡単に利用できるようになりました。さまざまなデプロイ環境(Inference Endpoints、Google Cloud、Amazon SageMaker)にも対応しています。
5. 柔軟なライセンス: Llama 3には派生利用が可能な、比較的緩いライセンスが適用されています。ただし、派生モデルにはLlama 3の由来を明示する必要があります。
また、モデルの評価や、TRLを使ったファインチューニングの方法など、Llama 3の活用方法についても詳しく解説されています。Llama 3は、オープンAI分野における重要な一歩となり、研究者や開発者の皆さんに大きな影響を与えるでしょう。
rinna、Llama 3 8Bに対して日本語データで事前学習を行った「Llama 3 Youko 8B」を開発

rinnaはこのたび、Meta社のLlama 3 8Bに対して日本語データで事前学習を行った「Llama 3 Youko 8B」を開発し、Meta Llama 3 Community Licenseの下で公開しました。
rinnaは、日本語に適したGPT、BERT、HuBERT、CLIP、Stable Diffusionなどの事前学習済みモデルを積極的に公開してきました。2021年4月からHugging Faceで公開したrinnaのモデルは累計560万ダウンロード、1000 Likesを超えており、多くの研究者や開発者に利用されています。
近年、Llama 3、Phi-3、OpenELMなどの高性能な大規模言語モデルが公開されましたが、これらのモデルは英語データを主に学習しているため、日本語のテキスト生成性能は十分ではありません。そこでrinnaは、Llama 2やQwenの日本語事前学習の知見を活かし、Llama 3の日本語モデル「Llama 3 Youko 8B」を開発しました。
Llama 3 Youko 8Bは、Llama 3 8Bのパラメータ数80億に対し、日本語と英語の学習データ220億トークンを用いて継続事前学習を行ったモデルです。Stability-AI/lm-evaluation-harnessのベンチマーク評価では、Llama 3の9タスク平均スコア59.82に対し、Llama 3 Youko 8Bは66.15と優れた性能を発揮しています。
Mistral AIは、新しいAIモデル「Mixtral 8x22B」を発表 スパース混合専門家(SMoE)モデルで高速かつ高機能

Mistral AIは、新しいAIモデル「Mixtral 8x22B」を発表しました。このモデルは、141Bのパラメーターのうち39Bだけが活性化されるスパース混合専門家(SMoE)モデルです。Mixtral 8x22Bは、コスト効率が非常に高く、70Bの密集モデルよりも高速で、他のオープンモデルよりも高機能です。このモデルは、英語、フランス語、イタリア語、ドイツ語、スペイン語に堪能であり、数学とプログラミングの能力が非常に高いです。64Kトークンのコンテキストウィンドウを持ち、大規模なドキュメントからの情報を正確に記憶できます。Apache 2.0ライセンスの下で公開され、誰でもどこでも制限なく使用できます。さまざまな標準業界ベンチマークで他のオープンモデルと比較して、推論、知識、多言語能力において優れた性能を発揮しています。特に、コーディングと数学のタスクにおいて、他のモデルを上回る性能を見せています。
東京工業大学ら、スーパーコンピュータ「富岳」で学習した大規模言語モデル「Fugaku-LLM」を公開

東京工業大学、東北大学、富士通、理化学研究所、名古屋大学、サイバーエージェント、Kotoba Technologies の研究チームは、スーパーコンピュータ「富岳」を用いて学習した大規模言語モデル「Fugaku-LLM」を2024年5月10日に公開しました。
このモデルは、以下のような特徴を有しています:
1. 「富岳」の性能を最大限に活用した分散並列学習を実現し、既存技術に比べて演算速度を6倍、通信速度を3倍に高速化しました。深層学習フレームワークの「富岳」への移植や、「富岳」向けの通信最適化などが行われています。
2. 130億パラメータのモデルで、現在の計算機環境下で扱いやすい程度の大規模さを持ち、日本語性能に優れています。国産の独自データで学習を行っているため、透明性と安全性が確保されています。
3. Japanese MT-Benchで最高性能を達成し、特に人文社会系のタスクで高いベンチマーク性能を発揮することが期待されています。敬語など日本語の特徴を踏まえた自然な対話が可能です。
今後は、このモデルを研究者やエンジニアが活用し、基盤モデルの改善や新たな応用研究に参画することで、効率的な学習方法や言語モデルの創出が期待されています。そして、科学シミュレーションと生成AIの連携による「AI for Science」や、数千を超える AIによるバーチャルコミュニティの社会シミュレーションなど、次世代の革新的な研究やビジネスの成果につながることが期待されています。
Stability AI, マルチモーダルなチャットボット「Stable Assistant」のベータ版を公開

Stable Assistantは、Stability AIによって開発された最新のテキストおよび画像生成技術を搭載したチャットボットです。現在ベータ版で利用可能であり、今後さらに機能が追加される予定です。Stable Assistantは、Stable Diffusion 3とStable LM 2 12Bを搭載しています。ベータ版へのアクセスは特定のリンクを通じて可能で、サブスクリプションは月額9ドルから開始できます。使用するごとにクレジットが消費され、画像生成には6.5クレジット、メッセージ送信には0.1クレジットが必要です。
8Bパラメータのマルチモーダルモデル「Idefics2」Hugging FaceがGoogleとMistralAIと共同で開発

Idefics2は、自然言語とイメージからなる入力に対して、文章での出力を生成できる強力な8B規模のマルチモーダルモデルです。Idefics1 から大幅な性能向上を実現しており、オープンソースでライセンスされています。
1. 8B個のパラメータを持つ大規模モデルで、多様な用途に利用可能です。オープンソースのため、コミュニティでの活用が期待されます。
2. 光学文字認識(OCR)の能力が強化されており、画像やドキュメントの文字情報を効果的に活用できます。
3. 画像の全体や部分を柔軟に扱うことができ、大きなサイズの画像にも対応しています。
4. 問題文や指示に基づいて、質問への回答やイメージの記述、複数のイメージに基づくストーリーの生成、計算処理などを行うことができます。
5. 事前学習後にさまざまなタスクに対してファインチューニングできるよう、Transformers ライブラリに統合されています。
6. コミュニティ向けにオープンソースデータセット「The Cauldron」を公開しており、多様なマルチモーダルタスクでの利用が期待されます。
Idefics2は、オープンソースで強力な性能を持つマルチモーダルモデルであり、コミュニティにとって有用な基盤となることが期待されます。開発にあたっては、Google チームやMistral AIなどの貢献に感謝しています。
RekaAI、マルチモーダルモデル「Reka Core」を発表 Snowflake、Oracleなどと提携

Reka Coreは、業界トップクラスのマルチモーダル言語モデルです。数か月にわたりGPUを使って効率的に学習されており、OpAI、Anthropic、Googleなどの最新モデルと肩を並べる性能を持っています。コストパフォーマンスの面でも優れており、多様な用途への活用が期待されます。
具体的な性能比較では、Reka Coreは画像・動画理解の「MMMU」タスクで、GPT-4Vと同等の成績を収めています。また、独立第三者機関による多モーダルの人間評価では、Claude-3 Opusを上回り、ビデオタスクでもGemini Ultraを凌駕しています。言語タスクでも、他の最新モデルと肩を並べる成績を収めています。
Reka Coreの主な機能としては、画像や動画、オーディオなどの多モーダルな理解能力、128Kもの長いコンテキストウィンドウ、高度な推論能力、コーディング能力、32か国語の多言語対応、オンプレミスやオンデバイスなど柔軟な展開が可能といった特徴が挙げられます。
Rekaは、このReka Coreをはじめ、Edge、Flash など一連の高性能モデルを提供しており、電子商取引、ヘルスケア、ロボティクスなど、様々な分野での活用を目指しています。パートナーには、Snowflake、Oracle、AI Singaporeなどの大手企業や組織が名を連ねており、多モーダル技術の普及に尽力しています。
小規模なモバイル向け言語モデル
Apple、オープンソースのLLM「OpenELM」発表 パラメータを効率的に配分することで高精度を実現

Appleが開発したオープンソースのLLMであるOpenELMは、パラメータを効率的に配分することで高精度を実現します。従来の実践とは異なり、OpenELMは公開されたデータセットを使ってトレーニングとテストを行うための完全なフレームワークを提供しています。また、MLXライブラリを使ってAppleデバイス上での推論とファインチューニングが可能です。このリリースは、オープンな研究コミュニティを支援し、未来の研究活動の基盤となることを目指しています。
OpenELMは、トランスフォーマーモデルのレイヤーごとのスケーリング戦略を採用することで、パラメータ数を約10億個に抑えつつ、既存の言語モデルOLMoに比べて2.36%の精度向上を実現しています。また、OpenELMのトレーニングには、OLMoの2倍少ない前処理トークンしか必要ありません。
OpenELMのリリースには、モデルの重みやインファレンスコードだけでなく、公開データセットを使ったトレーニングとテストの完全なフレームワークが含まれています。具体的には、トレーニングログ、複数のチェックポイント、前処理設定などが含まれています。さらに、Appleデバイス上での推論とファインチューニングを可能にするためのMLXライブラリへの変換コードも提供されています。
MLXは、Appleのデバイスでモデルを推論およびファインチューニングするために使用されるライブラリです。
Microsoftの小規模で高性能な言語モデル「Phi-3」

マイクロソフトは、小規模で高性能な言語モデル「Phi-3 ファミリー」を発表しました。このモデルは、少ないデータで訓練可能で、コンピューティングリソースの要求が低いため、広範な用途に適しています。「Phi-3-mini」は38億個のパラメータを持ち、そのサイズの2倍のモデルよりも優れた性能を発揮します。このモデルはMicrosoft Azure AI Model Catalog、Hugging Face、Ollamaなどで利用可能です。「Phi-3-small」と「Phi-3-medium」も近日中に発表される予定で、それぞれ70億、140億のパラメータを持ちます。小規模モデルは特にリソースが限られた環境や、迅速な応答が求められるアプリケーションに適しており、大規模モデルと組み合わせて使用されることが多いです。マイクロソフトは高品質のデータに基づいて小規模モデルを訓練し、デバイス上でローカルに実行可能であり、プライバシー保護とレスポンスの速さを兼ね備えています。モデルの選択は、使用する組織のニーズによって異なりますが、Phi-3 ファミリーは、その高性能とアクセスしやすさにより、多くの可能性を提供します。
ローカルLLM on iOS の現状まとめ

2024年3月5日に開催されたイベントで「ローカルLLM on iOS」に関する発表が行われ、その内容が記事として再構成されました。ローカルLLMはオフラインでも動作し、プライバシー保護が図られており、利用料が無料です。iOSデバイス上でLLMを動かす主な方法は、「llama.cpp」と「Core ML」の2つがあります。
- llama.cpp:C/C++で書かれた高速なランタイム。Georgi Gerganov氏によって開発され、GGMLからGGUFフォーマットへの変換が可能。Apple Silicon(ARM NEON、Accelerate、Metalフレームワーク)向けに最適化されています。量子化されたモデルがGGUFフォーマットで公開されており、すぐに試すことが可能。
- Core ML:Appleが開発したフレームワークで、iOSやmacOSに機械学習モデルを組み込むために使用。CPU、GPU、Neural Engineを利用して、メモリ使用量と電力消費を最小限に抑えつつパフォーマンスを最大化。Neural Engineを利用するためにはCore MLを通じてのみ可能。Hugging Faceが提供する「exporters」を使用して、TransformersモデルをCore MLモデルに変換可能。
現状、ローカルLLMのデモではモデルサイズや推論速度に課題がありますが、将来的にはデバイス性能の向上と量子化技術の進化により、オンデバイスでの動作が向上することが期待されています。MLXという新たな選択肢も提案されており、将来的にはiOS自体にローカルLLMがビルトインされる可能性も示唆されています。
新サービス
OpenAI、ChatGPT plusでチャットの内容を記憶させる機能「Memory」正式提供
OpenAIは、ChatGPTの機能「Memory」を、ChatGPT Plusユーザーに正式に提供開始いたしました。Memoryは、チャットの内容を記憶させることで、情報を繰り返す必要がなくなる機能です。初期設定でオンになっており、会議の要約を頼む際には、見出し、ポイントの箇条書き、最後のまとめを含ませるよう指示することができます。その際、返答に「Memory updated」と表示されることで、Memoryに記憶されたことが確認できるようになりました。
記憶された内容は、以降の依頼時に自動的に反映されるようになります。例えば、上記の例では「会議を要約して」と依頼するだけで、見出し、ポイントの箇条書き、最後のまとめを含む要約が提示されます。また、Memoryに記録された項目については、「Manage memories」ボタンからMemory管理画面に移行し、記録されたくない項目を削除することもできます。
さらに、EnterpriseおよびTeamsプランでもMemoryが利用可能になる見込みです。開発者自身のGPTのMemoryに記録した項目については、他のユーザーと共有されることはありません。
LLMで開発プロセス全体をサポートする「GitHub Copilot Workspace」
GitHub Copilot Workspaceは、開発者の環境を再定義する革新的な取り組みです。従来の開発プロセスにおける課題を解決するため、自然言語を用いて「アイデアから、コードへ、ソフトウェアまで」を一気に実現できる新しい体験を提供します。
GitHub Copilotは2022年に登場し、開発者の生産性を最大55%向上させる画期的なツールとなりました。2023年には、GitHub Copilot Chatが登場し、開発者がコードと対話しながら、デバッグやテストを行えるようになりました。そして今回、GitHub Copilot Workspaceが発表されました。
GitHub Copilot Workspaceでは、自然言語を用いて、課題の定義、仕様の作成、コード実装、テスト実行まで、開発プロセス全体をカバーします。Copilotエージェントがあなたのパートナーとなり、開発を支援してくれます。もちろん、すべての工程は編集可能で、開発者自身が主体的に関与できます。
GitHub Copilot Workspaceは、コードの生成や自動化だけでなく、開発者の創造性を発揮させることを目的としています。これにより、より高度な開発者がシステム思考に集中できるようになり、初心者でも気軽にソフトウェア開発に取り組めるようになります。
現在、世界では100万人を超える開発者がGitHubを利用しています。GitHub Copilot Workspaceは、自然言語によるプログラミングを推し進め、「10億人の開発者」の実現を目指します。同時に、プロフェッショナルな開発者の生産性を向上させ、ますます複雑化するシステムの保守・更新を支援することで、持続可能な開発環境の構築にも寄与します。
AWSの生成AIアシスタント「Amazon Q」一般提供開始

AWS(Amazon Web Services)は、生成AIアシスタント「Amazon Q」の一般提供を開始しました。また、社内データから生成AIアプリを構築できる新機能「Amazon Q Apps」も同時に発表しています。
「Amazon Q」は、開発者向けの機能が豊富です。コード生成や、テストやデバッグ、複数ステップの計画や推論(reasoning)機能を備えており、開発者のリクエストに応じて、コードの変換(Javaバージョンアップグレードの実行など)や新たなコードの実装が可能です。さらに、エンタープライズデータリポジトリに接続することで、企業のポリシー、製品情報、業績、コードベース、人材などさまざまな企業データに関する質問に答えることができ、データの論理的な要約やトレンドの解析、データに関する会話なども可能になっています。
「Amazon Q Apps」は、従業員が自然言語で業務アプリのニーズを記述するだけで、求める業務を遂行するアプリを生成できる機能です。これにより、効率的に日常業務を簡素化し、自動化することができます。
Anthropic、ClaudeのTeamプランとiOSアプリの提供を開始

最近、クロードチームはチームプランとiOSアプリの2つのアップデートを発表しました。
チームプランは、従業員全員がクロードとより多くのやり取りができるようにするものです。月額30ドル/ユーザーの料金で、クロード3モデル群(Opus、Sonnet、Haiku)の全機能を利用できるようになります。また、長文書類の処理や複雑なトピックの議論、マルチステップの会話ができる200,000トークンのコンテキストウィンドウ、ユーザー管理やビリング管理のための管理ツールなども備わっています。さらに、信頼できるソースからの引用、データリポジトリとの統合、同僚とのAI生成文書の共同作業など、今後の機能拡張も予定されています。
クロードiOSアプリは、クロードのウェブとシームレスに連携し、写真の撮影・アップロードや画像解析など、モバイルでの使用に適した機能を提供します。Pro、Teamユーザー全員が無料でダウンロードできます。
クロードは、個人だけでなく、チームを支援する最先端のAIアシスタントです。複雑な仕事のパートナー、専門家、創造的なコラボレーター、すぐに利用できるアシスタントとして、従業員の能力を向上させ、ビジネスの生産性を高めることができます。セキュリティとデータプライバシーにも配慮されており、組織の業務フローに合わせて活用できます。
Google、日本におけるGeminiのAndroid&iOSアプリの提供開始
グーグルは、生成AI「Gemini」アプリの日本展開を開始しました。Geminiは、Androidアプリとしてダウンロードできるほか、Googleアプリからもアクセス可能です。iOSユーザーはGoogleアプリからGeminiを利用することができます。
Geminiは、会話型かつマルチモーダルな機能を備えたAIアシスタントです。スマートフォンから、テキストの入力やカメラ撮影などを通じてさまざまなタスクを行うことができます。例えば、お礼メッセージの作成やパンクしたタイヤの修理方法の検索などが可能です。
Androidでは、Geminiアプリをダウンロードするほか、Google Assistantの起動方法(電源ボタンの長押しや「OK Google」の音声入力など)でもGeminiにアクセスできます。Geminiアプリには、Google Assistantの多くの機能(タイマー設定、通話、スマートホームデバイスのコントロールなど)が追加されており、今後さらに機能が拡張される予定です。
iOSではGoogleアプリからGeminiを利用可能で、SNS投稿のサポートや旅行計画の立案などの機能を使うことができます。
また、Geminiには拡張機能が用意されており、ユーザーはGmailやYouTubeなどのGoogleサービスと連携して、旅行計画の立案や動画視聴など、ワンストップで様々なタスクを行うことができます。ユーザーは、プライバシー設定や拡張機能の使用方法を自由に管理できます。
さらに、デスクトップ版のChromeでもGeminiを利用できる新しい方法が提供される予定です。Chromeのアドレスバーに「@gemini」と入力し、続いて質問を入力することで、Geminiが起動し、回答が表示されるようになります。
Stability AI, Stable Diffusion 3 APIを公開

Stable Diffusion 3 と Stable Diffusion 3 Turbo は、Developer Platform API で利用可能になりました。Stable Diffusion 3 は、DALL-E 3やMidjourney v6と比較して、タイポグラフィとプロンプトの忠実性が優れています。新しい Multimodal Diffusion Transformer (MMDiT) アーキテクチャは、画像表現と言語表現に別々のウェイトセットを使用しているため、テキスト理解とスペリング機能が向上しています。Stable Assistant Beta を通じて、画像モデルと言語モデルを組み合わせたコンテンツ作成が可能です。Fireworks AI との提携により、99.9%のサービス可用性を保証する API ソリューションを提供します。
Cohere、新しい基盤埋め込みモデル「Cohere Compass」のプライベートベータを発表

Cohereは、多様な側面を持つデータに対応できる新しい基盤埋め込みモデル「Cohere Compass」のプライベートベータを発表しました。多様な側面を持つデータとは、複数の概念や関係性を含むデータのことを指します。企業の保有するメール、請求書、履歴書、サポートチケット、ログメッセージ、表形式データなどがこれに該当します。
従来の埋め込みモデルは、単一の属性しか捉えることができませんでした。例えば、青と黄色のジーンズと緑と赤のTシャツが近い埋め込み結果を示してしまいます。これでは、「赤のTシャツ」を検索しても適切な結果が得られません。
Cohere Compassは、このような多様な側面を持つデータに対応するために設計されています。Compassでは、JSONドキュメントとして入力データを受け取り、ベクトルデータベースに多様な側面を捉えた埋め込み表現を保存します。
従来のRAGパイプラインでは、メールと添付PDFを別々に処理していましたが、Compassではメールとその添付ファイルを一つのJSON文書として取り扱い、メタデータと本文の関係性を保持した埋め込み表現を生成します。
Compassを使うと、「Cohere埋め込みのPRはいつのものですか?」といった、時間、意味上のトピック、タイプなどの複数の側面を組み合わせた検索クエリに適切に応答できるようになります。
Cohereは現在Compassのプライベートベータテストを行っており、多様な側面を持つデータを持つ企業の参加を募集しています。Compassの活用により、より高度な検索や分析が可能になることが期待されます。
画像・動画生成AI
エンドルフィン社の「ピュアモデルAI」は特定の漫画家の絵柄だけを学習させるAI

ピュアモデルAIは、エンドルフィン社が開発した、特定の漫画家の絵柄だけを学習させるAI技術です。この技術は、漫画家の里中満智子氏や倉田よしみ氏との協力により、それぞれの絵柄を忠実に再現することができます。Stable Diffusionをベースにして、特定の漫画家のスタイルを模倣するシステムは、漫画家との合意のもとでその漫画家の作品のサンプルを使用して訓練されます。このプロセスでは、少なくとも50枚の画像が必要で、より精密なファインチューニングを行う場合には追加の画像が必要になることがあります。また、韓国科学技術院(KAIST)との協力により、「Validator」というツールが開発されています。これは、アップロードされたイラストが既存のどのアーティストの作品に似ているかを識別し、著作権違反の可能性を評価するためのものです。このようなツールは、AIによる画像生成が一般化するにつれて、著作権保護において非常に重要な役割を果たすことが期待されています。
拡散ベースの生成モデルにおける画像や動画の一貫性を向上させる新しい手法「StoryDiffusion」

本論文では、拡散ベースの生成モデルにおける画像や動画の一貫性を向上させる新しい手法「StoryDiffusion」を提案しています。
従来の拡散ベースの生成モデルでは、複雑な詳細を含む画像を一貫して生成することが難しい課題がありました。StoryDiffusionでは、「一貫性を備えた自己アテンション」と呼ばれる新しい自己アテンションの計算方法を導入することで、この問題を解決しています。これにより、生成された画像の内容が一貫性を持つようになります。
さらに、長期の動画生成を実現するために、「Semantic Motion Predictor」と呼ばれる新たなモジュールを提案しています。このモジュールは、2つの入力画像からその間の意味的なモーションを予測することができ、生成された画像シーケンスをスムーズな遷移と一貫した被写体を持つ動画に変換します。従来のアプローチに比べ、特に長期の動画生成において、より安定した動画を生成できます。
これら2つの新しい手法を組み合わせた「StoryDiffusion」フレームワークにより、テキストベースのストーリーを、一貫性のある画像や動画で表現することができます。
Microsoft、一枚の静止画と音声クリップから、リアルタイムで話す顔のビデオを生成する「VASA-1」

Microsoftの研究チームがVASAというフレームワークを開発しました。これは、一枚の静止画と音声クリップから、リアルタイムで話す顔のビデオを生成する技術です。主要なモデルであるVASA-1は、音声に完璧に同期する唇の動きと、自然な頭の動きを含む顔のニュアンスを捉えることができます。この方法は、リアルタイムで人間の会話行動を模倣するアバターとの対話を可能にします。また、オプションの信号(主観視線方向、頭の距離、感情のオフセットなど)を条件として入力できるため、生成をコントロールできます。表情やポーズの編集が可能で、同じ写真で異なる動きのシーケンスを生成したり、異なる写真で同じ動きのシーケンスを生成することができます。512×512のビデオフレームをリアルタイムで45fpsで生成でき、オンラインストリーミングモードでは40fpsまでサポート可能です。この評価は、NVIDIA RTX 4090 GPUを搭載したデスクトップPCで行われました。現在、実際のビデオの認証性を達成するまでにはまだギャップがあるとのことです。
音声編集とゼロショットのテキストから音声への変換を行うニューラルコーデック言語モデル「VOICECRAFT」

VOICECRAFTは、音声編集とゼロショットのテキストから音声への変換(TTS)において、最先端の性能を達成したニューラルコーデック言語モデルです。このモデルは、オーディオブック、インターネット動画、ポッドキャストでの使用が評価されています。トランスフォーマーデコーダー構造を採用しており、因果マスキングと遅延スタッキングを組み合わせたトークン再配置手法を導入しています。これにより、既存のシーケンス内での生成が可能になります。音声編集タスクにおいては、編集後の音声が未編集の録音と自然さの面でほぼ区別がつかないレベルで生成されます。これは人間による評価で確認されています。ゼロショットTTSにおいては、既存の最先端モデルであるVALLEや商用モデルXTTS v2を上回る性能を示しています。評価は、多様なアクセント、話し方、録音条件、背景音楽や騒音が含まれる現実的なデータセットで行われており、他のモデルや実際の録音と比較して一貫して良好な成績を収めています。デモはウェブサイトで聞くことができ、そのURLは公開されています。
ディープラーニング新技術
新しいニューラルネットワークアーキテクチャ「Kolmogorov-Arnold Networks(KAN)」各エッジに可変の活性化関数を持つ

本文では、Kolmogorov-Arnold Networks(KAN)と呼ばれる新しいニューラルネットワークアーキテクチャが提案されています。従来のMulti-Layer Perceptrons (MLP)では、各ノード(ニューロン)に固定の活性化関数が使用されるのに対し、Kolmogorov-Arnold Networks (KAN)では、各エッジ(重み)に可変の活性化関数を持つことが特徴です。
KANは、線形の重みパラメータを一切持たず、代わりにスプラインで表現された1変数の関数を重みパラメータとして使用します。この単純な変更により、KANはMLPに比べて優れた性能を示すことが示されています。
具体的には、データフィッティングやPDE(偏微分方程式)の解法において、KANsはMLPsよりはるかに小さなネットワークサイズで同等以上の精度を達成できることが示されています。また、理論的および経験的に、KANsはMLPsよりも高速なニューラルスケーリング則を持つことが明らかになっています。
さらに、KANsは直観的に可視化できるため、人間ユーザーとの良好な相互作用が期待できます。数学と物理学の2つの具体例を通して、KANsは科学者による数学的・物理学的法則の発見や再発見を支援する有用なツールとなることが示されています。
以上のように、KANsはMLPsの有望な代替手段として、今日の深層学習モデルをさらに改善する機会を提供するものと期待されています。
LLM新技術
NTT、深層学習で過去の学習過程を新しいモデルに再利用する「学習転移」技術発表

NTTは、深層学習の分野において、過去の学習過程を新しいモデルに再利用する「学習転移」技術を世界で初めて実現しました。この技術は、ニューラルネットワークのパラメータ空間における高い対称性を活用し、適切な変換を行うことで、既存モデルの学習結果を低コストで得ることを可能にします。
これにより、生成AIなどの大規模な基盤モデルを用途に合わせてチューニングする際の再学習コストを大幅に削減できます。例えば、NTTが開発している大規模言語モデル「tsuzumi」の更新や、異なる基盤モデルへの変更時に必要となる再チューニングの手間を軽減することができます。
学習転移の技術的なポイントは次のとおりです。
1. 学習転移を2つのパラメータ初期値間の最適な置換変換を求める最適化問題として定式化しました。これは世界で初めての試みです。
2. 未知のターゲットの学習過程を勾配で近似し、部分的な転移と線形最適化を交互に行うことで、高速にアルゴリズムを導出しました。
3. 理論的に、ネットワークサイズが大きくなればなるほど、ソースの初期学習過程をターゲットに近づけられる確率が高くなることを証明しました。
今後、この学習転移技術によって、生成AIの運用コスト削減や消費電力の削減、さらには多数のAIを用いた「AIコンステレーション」の実現など、次世代のAI技術開発に貢献することが期待されています。本成果は2024年5月にウィーンで開催されるICLR 2024で発表される予定です。
NTT、GPT-4を上回る性能の視覚読解技術を開発
NTTは、図表やグラフを含む文書を理解するための「視覚読解技術」を開発し、この技術を「tsuzumi」というLLMに採用しました。この技術は、文書画像を画像情報に変換し、LLMが読解するというプロセスを経ています。アダプター技術により、画像エンコーダーとLLMの間をつなぎ、効率的な学習が可能です。視覚読解技術は、未学習のタスクでも優れた性能を発揮し、「GPT-4」に匹敵、またはそれを上回る性能を実現しています。NTTはこの技術を用いて、カスタマーサポートの助けや作業の自動化など、デジタルトランスフォーメーション(DX)の推進に貢献することを目指しています。この技術は、東北大学との共同研究の成果であり、国際会議「AAAI2024」での採択も受けています。
韓国科学技術院(KAIST)、RAGに質問分類させる「Adaptive-RAG」を提案
「Adaptive-RAG」とは、質問の複雑さに応じて最適な回答戦略を選択する技術です。これは韓国科学技術院(KAIST)の研究者によって提案された手法で、RAG(Retrieval-Augmented Generation)の回答精度を向上させる目的で開発されました。この技術は、シンプルな質問から複雑な質問までを分類し、質問の種類に基づいて適切な回答プロセスを選択します。簡単な質問には検索を伴わない回答を、複雑な質問には複数回の検索を伴う回答を行うことが特徴です。「Adaptive-RAG」の核となるのはClassifier(分類器)で、これにはT5という言語モデルをファインチューニングして使用します。この分類器は質問の難易度を自動で識別し、その情報を基に最適な回答戦略を選択します。複数のオープンドメインQAデータセットでの評価により、この手法は従来のRAG手法と比べて効率と精度の両方を向上させることが確認されています。特に複雑な質問に対しては、より時間をかけて高精度な回答を生成することができるようです。「Adaptive-RAG」は、実際の業務での利用価値が高いとされ、特に時間と精度のバランスが求められる環境での応用が期待されています。ただし、質問の正確な分類がこのシステムの成否を左右するため、分類器の精度向上が今後の課題となっています。
数百~数千の事例を利用した場合のLLMの性能調査 Many-Shot In-Context Learning

インコンテキスト学習(In-Context Learning)は、特に大規模言語モデルが使用する学習手法の一つです。この方法では、モデルに特定のタスクを実行させるために、具体的なトレーニングフェーズを設けず、モデルの既存の知識を利用して新しい情報やタスクを処理します。
具体的には、モデルに入力される文脈(コンテキスト)内で、タスクの説明や関連する例(デモンストレーション)が与えられます。モデルはこれらの情報を参照しながら、新たな問題に対する解答や適切な反応を生成します。この過程で、モデルは文脈の中からタスクの解決に必要な情報やパターンを抽出し、それを基にして新しい問いに答える能力を示します。
モデルが過去に学習した情報や一般的な知識を基にして、特定の問題を即座に解決する能力に依存しているため、追加のトレーニングデータに依存せずに柔軟な応用が可能です。これは、特にリアルタイムでの問題解決や新しいタイプの問題に対応する場合に有効です。
本論文では、大規模言語モデル(LLM)による「多量の事例によるインコンテキストラーニング(Many-Shot In-Context Learning)」について報告されています。
従来のLLMは、わずかな事例(few-shot)から容易にインコンテキストでの学習ができることが知られていますが、本研究では、数百~数千の事例(many-shot)を利用した場合の性能を調べています。その結果、生成タスクや識別タスクにおいて大幅な性能向上が見られました。
しかし、many-shotの学習には人間が生成した多数の事例が必要になるという課題がありました。そこで、本研究では2つの新しい手法を提案しています。
1つは「Reinforced ICL」です。これは、人間が生成した事例の代わりに、モデル自身が生成したチェーン・オブ・シンキング(論理的な推論過程)を利用するものです。もう1つは「Unsupervised ICL」で、ドメイン固有の質問のみを提示し、事例そのものは与えないというものです。
これらの手法を使うことで、複雑な推論タスクにおいても、many-shotの学習が効果的であることが示されました。また、few-shotの学習とは異なり、many-shotの学習では、事前学習時のバイアスを上書きし、数値入力を持つ高次元の関数を学習することができることが分かりました。
一方で、次トークン予測の損失関数では、下流のインコンテキストラーニングの性能を十分に捉えられない可能性も示唆されています。
大規模なコンテキストを用いたin-context learningの振る舞い調査

最近の言語モデルはコンテキストの長さが大幅に増加しており、モデルへ与えることができるデモンストレーション(入力と出力のペア)の数は、トレーニングデータセットの大きさに近づきつつあります。本論文では、このような大規模なコンテキストを用いたin-context learning(ICL)の振る舞いを多様なデータセットとモデルについて調査しています。
多くのラベルの多い大規模なデータセットにおいて、ICLの性能は数百から数千のデモンストレーションを与えることで向上し続けることが示されました。一方で、単純な例の検索やファインチューニングでは、コンテキストの長さが短い場合に優れた性能を示すものの、デモンストレーションが増えるに従って性能向上が飽和してしまうことが確認されました。ファインチューニングはICLよりもデータ効率が低いものの、さらに多くのデータが利用できる場合は、長いコンテキストを用いたICLを上回る性能を発揮することもあるようです。
著者らはこのICLの設定を利用して、ICLおよび大規模コンテキストモデルの特性をさらに詳しく分析しています。長いコンテキストを用いたICLは、短いコンテキストを用いたICLよりもランダムな入力並び替えに対して頑健であることや、同じラベルの例を纏めて提示するとかえって性能が低下することなどが報告されています。また、多数の例を一緒にエンコーディングすることで得られる性能向上は、単に同様の例を参照しているだけによるものであって、タスク学習そのものの向上によるものではないことも確認されました。
以上のように、長いコンテキストを用いたICLは驚くべき効果を発揮し得るものの、その大部分は多数の類似した例を参照できることによるものであり、実際のタスク学習の向上には限界があることが示唆されています。
LLMを使ってWikipedia風の記事を執筆する「STORM」

本研究は、大規模言語モデルを使用して、Wikipedia のようなグラウンディングされた長編記事を最初から作成する方法について調査しています。この問題は、事前執筆段階における新たな課題を提起します。具体的には、トピックを調査し、執筆前にアウトラインを準備する方法についてです。
研究者らは、STORM と呼ばれる執筆システムを提案しています。STORM は、事前執筆段階をモデル化しています。その手順は以下の通りです:
1. 与えられたトピックについて、多様な視点を発見する
2. トピックの専門家と行われる対話を模倣し、さまざまな視点から質問を受ける
3. 収集した情報をキュレーションし、アウトラインを作成する
評価のために、研究者らは FreshWiki と呼ばれるデータセットを作成しました。これは、最近公開された高品質な Wikipedia 記事から構成されています。そして、アウトラインの評価方法を定義しています。さらに、経験豊富な Wikipedia 編集者からフィードバックを得ています。
STORM によって生成された記事は、アウトラインが整理されている (絶対値で 25% 増加) と評価されており、カバー範囲も広い (10% 増加) と評価されています。専門家からのフィードバックにより、グラウンディングされた長編記事の生成における新たな課題も明らかになりました。具体的には、ソースの偏りの転移や、関連性の低い事実の過剰な関連付けなどが挙げられます。
LLMを複数のトークンを同時に予測するように訓練することで高速推論が可能に

大規模言語モデルであるGPTやLlamaは、次のトークンを予測するロスを用いて訓練されています。この研究では、複数のトークンを同時に予測するように訓練することで、より効率的にサンプルを利用できることを示しています。具体的には、訓練コーパス内の各位置で、モデルが共通のモデルトランクを使って、n個の独立した出力ヘッドを用いて、次のn個のトークンを予測するよう求めます。これを補助課題として利用することで、コードおよび自然言語モデルの、下流での能力が向上することを確認しました。この手法は、モデルサイズが大きくなるほど有効で、複数エポックにわたる訓練でも有効です。特に、コーディングなどの生成タスクで大きな性能向上が見られ、13Bパラメータのモデルは、HumanEvalで12%、MBPPで17%、次トークン予測モデルよりも多くの問題を解決できました。また、小規模な算法タスクの実験からは、複数トークン予測が、帰納的ヘッドや算法推論能力の向上に有効であることがわかりました。さらに、4トークン予測で訓練したモデルは、大きなバッチサイズでも最大3倍の高速推論が可能です。
LLMの評価
LLMのコード生成機能を計測するベンチマーク「LiveCodeBench」

LiveCodeBenchは、UC Berkeley、MIT、Cornellの研究者によって開発された新しいベンチマークで、LLMのコード生成機能を計測することができます。
LiveCodeBenchは、さまざまなコーディングコンテストプラットフォームから蓄積されたコーディング問題を利用しています。問題にはリリース日が付与されており、異なる時間枠の問題集合で評価することで、 “経時的な評価” が可能になり、汚染を防ぐことができます。コード生成タスクに加えて、自己修復、テスト出力予測、コード実行なども評価することで、次世代のAIプログラミングエージェントに求められる総合的なコーディング能力を把握することができます。
LiveCodeBenchの問題は、LeetCode、AtCoder、CodeForcesといったコーディングコンテストプラットフォームから収集されています。これらのサイトでは定期的にコンテストが開催され、参加者のコーディングやプロブレムソルビングのスキルを評価する問題が出題されます。問題には自然言語の問題文と入出力例が含まれ、隠されたテストケースに合格するプログラムを作成することが目標となっています。
LiveCodeBenchでは次の4つのシナリオを使って評価を行います。
1. コード生成: 問題文と入出力例が与えられ、正しいソリューションコードを生成することが求められます。生成されたコードの機能的な正しさで評価されます。
2. 自己修復: 問題文とプログラム候補が与えられ、エラーフィードバック(例外メッセージや失敗したテストケース)を受けて修正を行うことが求められます。機能的な正しさで評価されます。
3. コード実行: 関数(f)とテスト入力が与えられ、その出力を予測することが求められます。実行ベースの正解判定基準で評価されます。
4. テスト出力予測: 問題文とテストケースの入力が与えられ、期待される出力を生成することが求められます。完全一致で評価されます。
ヘルスケア分野におけるLLMの性能を評価する「The Open Medical-LLM Leaderboard」

「The Open Medical-LLM Leaderboard」というリーダーボードは、ヘルスケア分野における大規模言語モデル(LLM)の性能を評価するためのものです。
主な特徴は以下の通りです。
1. 様々な医療分野のデータセットを使って、LLMの医療知識とQA能力を包括的に評価します。データセットには、MedQA、PubMedQA、MedMCQAなどが含まれています。
2. 主な評価指標は正答率(Accuracy)です。提出されたモデルはこの指標に基づいて順位付けされます。
3. 現在のリーダーには、GPT-4やMed-PaLM-2といった商用モデルと、Starling-LM-7BやGemini Proといった研究用モデルが名を連ねています。
4. モデルの提出方法や、今後の展開について詳しく解説されています。例えば、モデルをsafetensorsフォーマットに変換したり、AutoClassesとの互換性を確認する必要があります。
5. 今後はより多様なデータセットの導入や、新しい評価指標の検討など、リーダーボードの機能拡張が予定されています。
LLMの小学校レベルの算術問題に対するパフォーマンス調査

この論文は、大規模言語モデル(LLM)の小学校レベルの算術問題に対するパフォーマンスを詳しく調べたものです。数学的推論の多くのベンチマークで顕著な成功を達成していますが、その性能がデータセットの汚染によるものであるという懸念が高まっています。データセットの汚染とは、ベンチマークの質問に酷似したデータが訓練データに漏れることを指し、真の推論能力を反映していない可能性があります。
研究者らは、この問題を調査するため、GSM1k(Grade School Math 1000)というベンチマークを開発しました。GSM1kは数学的思考力を測る標準ベンチマークGSM8kベンチマークと同程度の難易度を持っているため、LLMの実際の推論能力を評価することができます。
オープンソースおよびクローズドソースの主要なLLMをGSM1kで評価したところ、最大13%の精度の低下が観察され、いくつかのモデルファミリー(例:Phi、Mistral)はほとんどすべてのモデルサイズで体系的な過学習の証拠を示しています。一方で、最先端のモデル(例:Gemini/GPT/Claude)は過学習の兆候が最小限であることが確認されました。
さらなる分析により、モデルがGSM8kから例を生成する確率とGSM8kとGSM1kのパフォーマンスギャップの間に正の関係(Spearmanのr^2=0.32)があることが示され、多くのモデルがGSM8kを部分的に記憶している可能性があることが示唆されています。
この研究は、LLMの数学的推論能力を正確に評価するためのアプローチを提示しています。GSM1kベンチマークは、LLMの真の推論能力を測るための有用なツールとなり得ます。また、過学習の傾向が見られたモデルについては、さらなる改善の余地があると考えられます。今後、LLMの数学的能力をさらに向上させるための取り組みが期待されます。
AIの活用
Google DeepMindとIsomorphic Labs、生命分子の構造を予測するAI「AlphaFold 3」
AlphaFold 3は、Google DeepMindとIsomorphic Labsによって開発された新しいAIモデルです。タンパク質、DNA、RNA、リガンドなどあらゆる生命体の分子の構造と相互作用を高精度に予測するこのモデルは、生物学的世界の理解と創薬の変革をもたらすことが期待されています。
AlphaFold 3は、2020年に大きな進展を遂げたAlphaFold 2を基に構築されています。これまでにも多くの研究者がAlphaFold 2を使ってマラリアワクチンやがん治療薬、酵素設計などの分野で重要な発見をしてきました。AlphaFold 3は、タンパク質だけでなく、広範な生体分子の予測が可能になりました。これにより、バイオ素材の開発や作物の強靭化、創薬の高速化、ゲノム研究の加速など、さらなる画期的な科学的進歩が期待されています。
AlphaFold 3の予測能力は飛躍的に向上しており、既存の手法と比べて、タンパク質と他の分子種の相互作用予測精度は50%以上向上し、重要な分類では2倍の精度となっています。特に、タンパク質とリガンド、抗体との結合予測精度が飛躍的に向上しており、創薬につながる重要な知見が得られます。
AlphaFold Serverは、この技術を誰もが無料で利用できるようにするためのプラットフォームです。実験による蛋白質構造予測には膨大な時間とコストがかかりますが、AlphaFold Serverを使えばタンパク質、DNA、RNA、リガンド、イオンなどの構造を簡単に予測できるようになります。これにより、研究者は実験前に仮説を立て、効率的に検証できるようになります。
AlphaFold 3の開発にあたっては、バイオセキュリティや研究、産業界など、50以上の専門家と協議し、リスクの軽減と利益の最大化に取り組んできました。今後も、無料のデータベースの提供や教育プログラムの拡充、開発途上国への支援など、責任を持って技術の普及を進めていきます。
AlphaFold 3は、生命体の分子システムを鮮明に描き出すことで、創薬や疾患理解、持続可能な農業など、さまざまな分野での飛躍的な進展を実現する可能性を秘めています。この技術を活用し、生物学における新たな発見と革新を生み出していくことが期待されます。
Geminiモデルをベースとした医療分野に特化したモデル「Med-Gemini」

医療分野における人工知能の適用には多くの課題が存在します。高度な推論能力、最新の医学知識へのアクセス、複雑な多様なデータの理解が必要とされるためです。しかし、多様なモーダルデータと長文脈の理解が可能な「Gemini」モデルは、医療分野での活用が期待されています。
本研究では、Geminiモデルをベースに、医療分野に特化した「Med-Gemini」モデルを提案しています。Med-Geminiは、ウェブ検索を自在に利用でき、カスタムエンコーダを使って新しいモーダルデータにも適応できる高性能なマルチモーダルモデルです。
14の医療ベンチマークで評価した結果、Med-Geminiは10項目で最新技術水準(SoTA)を達成し、GPT-4を大幅に上回る成績を収めました。特に、MedQA(USMLE)ベンチマークでは91.1%の精度を実現しており、また7つのマルチモーダルベンチマークでは平均で44.5%の相対的な性能向上を示しました。
さらに、Med-Geminiは長文脈理解能力に優れており、長い匿名化された健康記録からの情報検索や医療動画の質問応答で最高水準の性能を発揮しました。これらの結果は、医療テキストの要約や医療対話、医療研究・教育など、実用面での有用性を示唆しています。
OpenAIニュース
Stack OverflowとOpenAIが新たなAPI連携を発表
本日、株式会社Stack OverflowとOpenAIが新たなAPI連携を発表しました。この提携により、技術的な内容に関する世界最大のナレッジプラットフォームであるStack Overflowと、最も人気のあるLLMモデルを提供するOpenAIが協力し、開発者の皆さまにさらに便利なサービスを提供することになります。
具体的には以下のような取り組みが行われます。
1. OpenAIはStack OverflowのOverflowAPIを活用し、ユーザーや開発者にとってより良いAIモデルの構築を行います。また、ChatGPT上でStack Overflowのコミュニティから提供される信頼性の高いテクニカルな知識やコードを表示することで、ユーザーが簡単にアクセスできるようになります。
2. Stack Overflowは、OpenAIのモデルを自社のOverflowAIの開発に活用し、内部テストの結果をOpenAIにフィードバックすることで、OpenAIモデルのパフォーマンス向上に貢献します。これにより、Stack Exchangeコミュニティのヘルス、成長、エンゲージメントの向上につなげていきます。
2024年前半にはこの連携による新たな機能や統合が提供される予定です。
OpenAI、DALL·Eの生成画像を検出するためのバイナリー分類器をAPI経由で提供 研究向け

DALL·Eの生成画像を検出するためのバイナリー分類器が、API経由で提供されています。この分類器を利用することで、画像がDALL·E 3によって生成されたものか否かを判定することができます。分類結果は真/偽のバイナリー値と、DALL·E 3による生成画像である可能性を示す連続数値スコアとして返されます。
この取り組みの主な目的は、分類器の有効性評価、実世界での活用事例の検討、AI生成コンテンツの分析、および責任ある利用のための考察など、独立した研究を促進することにあります。研究者には、この取り組みを支援するためのAPIクレジットが割り当てられます。
興味のある研究分野としては、分類器のパフォーマンス評価、医療画像や写真リアルな画像シミュレーションなど、多様な画像タイプでのストレステスト、バイアスや改ざん/敵対的画像に対する耐性の検証、人間の能力との比較評価などが挙げられます。
また、分類器を活用する意思決定プロセスの特定、利用に当たっての留意事項の明確化、情報流通への影響の検討、ファクトチェッカーなどのステークホルダーに向けた活用ガイドラインの策定なども重要な研究テーマとなります。
さらに、オンラインの様々な環境におけるAI生成画像の実態把握や特徴分析なども、この取り組みの一部として位置づけられています。
これらの研究を支援するため、研究機関やNPO等の団体には、機密保持契約(NDA)の締結が求められます。これにより、DALL·E Detection Classifierを活用した研究成果の事前審査が可能となり、その成果の信頼性が担保されます。
OpenAI、コンテンツのスクレイピングを遮断するツール「Media Manager」の開発を進める

AI時代におけるコンテンツ利用の在り方について、OpenAIは新しい仕組み作りに取り組んでいます。「Media Manager」と呼ばれる新しいツールの開発を進めており、2025年までの提供を目指しています。これにより、コピーライトで保護されたテキスト、画像、音声、動画のAIによる利用について、クリエイターの意向を反映できるようになります。
一方で、OpenAIのAIモデルは、単にデータベースとしてコンテンツを蓄積するのではなく、関係性を学習して新しいコンテンツを生み出す「学習機械」として設計されています。そのため、稀に既存のコンテンツの一部を繰り返してしまうことがありますが、それは学習プロセスの課題であり、継続的な改善により克服していきます。
また、OpenAIのAIモデルは、できる限り多様な言語、文化、分野のデータを学習することで、広範な領域でより役立つものになるよう設計されています。オープンデータや提携先からのデータを活用しており、個人情報の取り扱いには十分な配慮をしています。
OpenAI、APIやChatGPTを利用する際のモデルの行動原則を定めた「Model Spec」発表

Model Specは、OpenAIのAPIやChatGPTを利用する際のモデルの行動原則を定めたものです。ユーザーとの対話の中で、モデルが適切な言動を心がけるようにするためのガイドラインです。具体的には、次の3つの要素から構成されています。
1. 目的:モデルの行動が目指すべき大まかな方向性を示す原則
2. ルール:複雑な状況に対応し、安全性と合法性を確保するための具体的な指示
3. デフォルトの行動:目的とルールに沿った一般的な対応の仕方を示すガイドライン
これらのガイドラインに基づいて、モデルは適切な情報提供やアドバイスを心がけるようになります。例えば、不法な行為に関する相談には答えず、医療や金融に関する専門的な助言は控えめにする、といった具合です。
モデルの行動を設計する際には、さまざまな観点からのトレードオフが伴うため、OpenAIでは今後、広範な関係者からのフィードバックを得ながら、Model Specの改善に取り組んでいく予定です。これは、AIの振る舞いをめぐる議論を深めていくための継続的な取り組みの一環といえます。
新聞社とLLM
日本経済新聞、40年分の記事を学習させた経済特化AI「NIKKEI Language Model」

日本経済新聞社は、経済情報に特化した生成AI「NIKKEI Language Model」を開発しました。このAIは約40年分の日経グループの新聞や雑誌の記事から学習しています。「NIKKEI Language Model」には、パラメーター数130億と700億の2種類があります。130億のモデルは独自に構築され、日経グループが持つデータを学習しています。700億のモデルは、米メタの「Llama(ラマ)2」をベースにファインチューニングされて開発されました。これは外部の改良が認められているモデルです。開発されたAIは、最新ニュースに関する知識を持ち、記事の要約機能などで性能を発揮することが確認されています。日経イノベーション・ラボは2019年から言語モデルの研究を進めており、AIが不正確な情報(ハルシネーション)を生成する問題などに対処してきました。日経はAIを用いた記事の生成や編集を行っておらず、「責任ある報道は人が担う」という方針を持っていますが、要約や再構成にはAIを利用しています。
英フィナンシャル・タイムズ、OpenAIと戦略的パートナーシップとライセンス契約を締結

- フィナンシャル・タイムズ(FT)は、人工知能(AI)のリーダーであるOpenAIとの戦略的パートナーシップおよびライセンス契約を発表しました。
- このパートナーシップにより、ChatGPTはFTのジャーナリズムから引用されたコンテンツを組み込むことで、モデルの有用性を向上させることを目指します。
- FTは、従業員全員がChatGPT Enterpriseへのアクセスを購入し、AIツールによる創造性や生産性の向上を図っています。
独アクセル・シュプリンガー、OpenAIとパートナーシップを発表 記事の要約を提供

- Axel Springerは、AI技術におけるジャーナリズムの深い統合を目指してOpenAIとのグローバルパートナーシップを発表しました。
- このパートナーシップは、独立したジャーナリズムをAI時代において強化することを目的としており、ChatGPTのユーザー体験を最新かつ権威あるコンテンツで豊かにすることを目指します。
- ChatGPTユーザーは、Axel Springerのメディアブランドから選ばれたグローバルニュースの要約を受け取り、透明性を高めるために完全な記事への帰属とリンクが含まれます。
- この提携により、Axel SpringerはOpenAIの技術を活用した既存のAI主導の事業をサポートし、OpenAIの高度な大規模言語モデルのトレーニングにも質の高いコンテンツが利用されます。
仏ル・モンド、西プリサ・メディア、OpenAIとパートナーシップを締結

- OpenAIは、フランスのLe MondeおよびスペインのPrisa Mediaとのパートナーシップを通じて、フランス語とスペイン語のニュースコンテンツをChatGPTに取り入れました。
- このパートナーシップにより、ChatGPTユーザーはLe MondeとPrisa Mediaが提供する最新の出来事に関する高品質なコンテンツに触れることができるようになります。
Alden Global Capitalの傘下にあるアメリカの新聞社、MicrosoftとOpenAIを訴える

OpenAIとMicrosoftは、2024年4月30日に、New York Daily NewsやChicago Tribuneを含む8社の新聞社から著作権侵害で訴えられました。
これらの新聞社は、OpenAIが新聞のテキストを含むデータセットを利用してGPT-2やGPT-3などの大規模言語モデルをトレーニングしたと主張しています。また、Microsoftは新聞から情報をコピーしてBingの検索インデックスを作成し、Copilotで記事に関する回答を提示しているとも指摘されています。これらの新聞社は、何百万もの著作権で保護された記事を許可なく無料で使用していると主張し、ニューヨーク州南部地区連邦裁判所に訴訟を提起しました。
ニュース
Googleの親会社Alphabet、クラウドと広告が好調で2桁台の増収増益
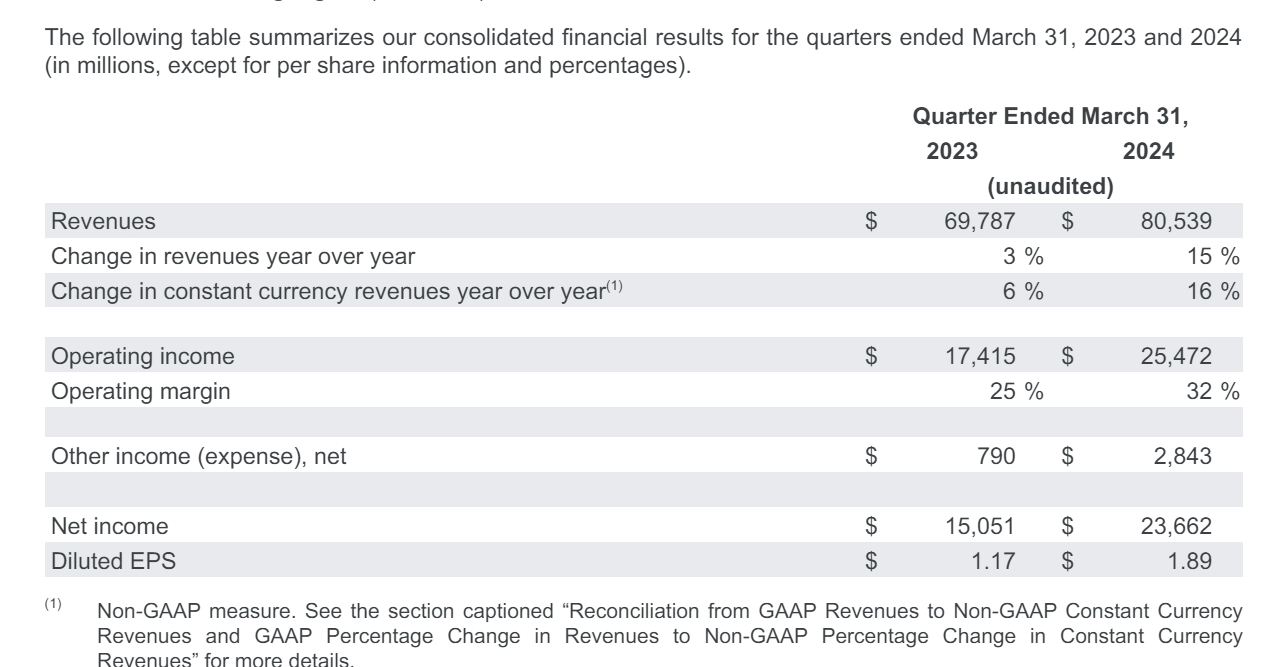
米Alphabet社は2024年第1四半期の決算を発表し、売上高は前年同期比15%増の805億3900万ドル、純利益は57%増の236億6200万ドルとなりました。これにより、3四半期連続で売上高が2桁台で増加しました。主力の広告部門の売上は13%増の626億6000万ドル、YouTube広告は21%増と特に好調でした。クラウド部門も28%増の95億7400万ドルと大きく伸び、営業利益は約4倍の9億ドルに達しました。その他の事業部門である「Google subscriptions, platforms, and devices」の売上は18%増加しましたが、「Other Bets」部門は72%増の売上でありながら営業損失は前年比で減少しました。Alphabetはこの四半期に、AI技術の強化のためサーバーやデータセンターへの投資を含め120億ドルを設備投資に費やし、また研究開発に119億ドルを支出しています。CEOのスンダー・ピチャイは「Gemini時代が順調に進んでおり、社内全体で大きな勢いが高まっている」とコメントしており、AIイノベーションに向けて好位置にあると述べています。
Microsoft、AI需要で2桁台の増収増益
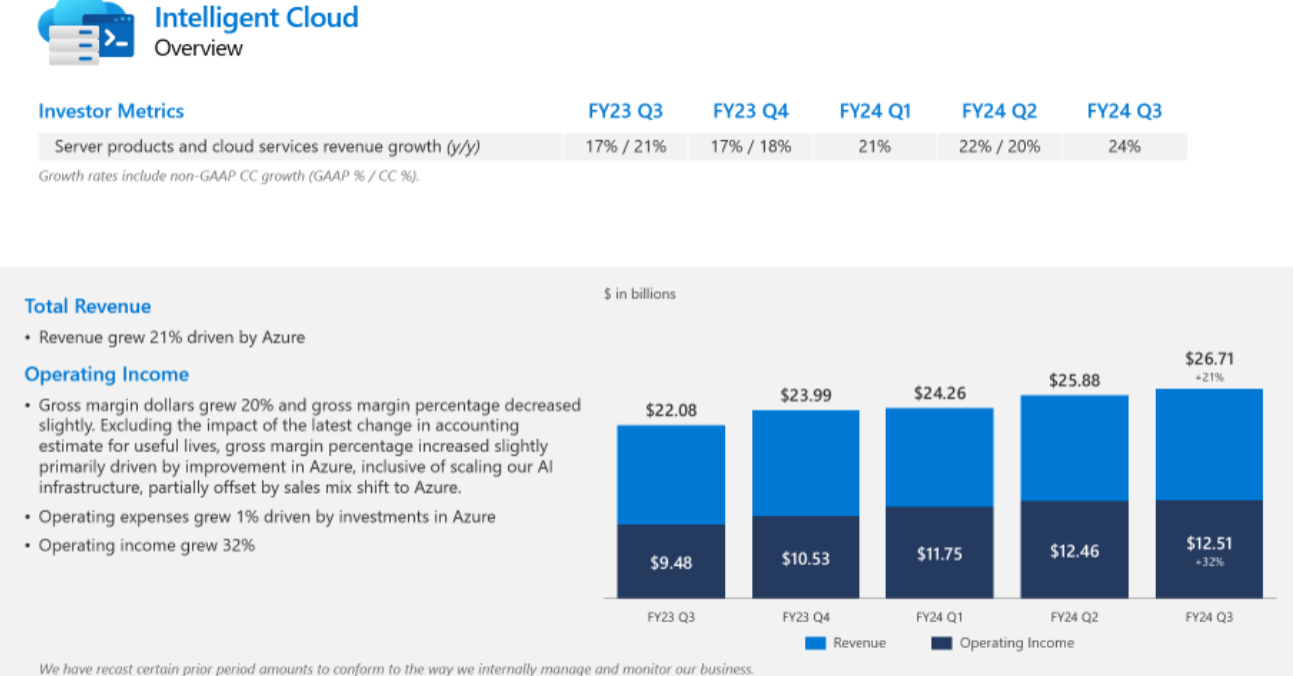
米Microsoftが2024年第3四半期の決算を発表し、売上高は前年同期比17%増の618億5800万ドル、純利益は20%増の219億3900万ドルでした。AI統合を進めたクラウド部門が順調で、特に「Copilot」製品が推進力となっています。Intelligent Cloud部門の売上高は24%増の267億1000万ドルで、Azureを含むクラウドサービスの売上が31%増加しました。AIサービスからの寄与は7ポイント含まれています。Productivity and Business Processes部門では、OfficeやLinkedIn、Dynamicsの売上高が12%増の195億7000万ドルで、特に企業向け「Office 365」の売上が15%増でした。More Personal Computing部門の売上高は17%増の155億8000万ドルで、デバイスの売上は17%減少しましたが、企業向けSurfaceの新モデルが発売されました。第4四半期の売上高は640億ドルと予測され、現在AI需要がMicrosoftの能力を若干上回っている状況です。
Appleが2024年度第2四半期の決算を発表、減収減益

Appleは2024年度第2四半期(1~3月)の決算を発表しました。売上高は前年同期比で4%減の908億ドル(約13兆9000億円)、純利益は前年同期比で2%減の236億ドル(約3兆6200億円)です。主力製品のiPhone、iPad、Macなどの売上は全体的に減少していますが、サービス部門だけが好調を維持し、14%増の239億ドル(約3兆6600億円)を記録しました。iPhoneの売上は460億ドル(約7兆500億円)で10%減、iPadは55億6000万ドル(約8520億円)で17%減、Macは74億5000万ドル(約1兆1400億円)で4%増です。Appleはこの四半期に過去最高額となる1100億ドル(約16兆9000億円)の自社株買い戻しを実施しました。
Microsoft、アジアの生成AI・クラウドに巨額投資
日本に29億ドル

UAEに15億ドル

インドネシアに17億ドル

マレーシアに22億ドル

国内ニュース
総務省、LINEヤフーに2度目の行政指導 資本関係見直しの具体化を要求

総務省は、LINEヤフーに対して2度目の行政指導を行いました。これは2023年11月に発生した不正アクセスと情報漏洩に関連しています。LINEヤフーは迅速な対策を講じたものの、総務省はこれを不十分と判断しました。具体的には、セキュリティ管理や委託先管理の抜本的な見直し、親会社を含むグループ全体でのセキュリティガバナンスの構築が不十分であると指摘されました。総務省は、資本関係と経営体制の見直しを含め、さらなる対策と具体的な計画の提出を7月1日までに要求しています。また、親会社のソフトバンクに対しても、セキュリティガバナンスの確保策を検討するよう指示しています。
→ 2024-04-16 “総務省|報道資料|LINEヤフー株式会社に対する通信の秘密の保護及び サイバーセキュリティの確保の徹底に向けた措置(指導)” https://www.soumu.go.jp/menu_news/s-news/01kiban18_01000230.html
オラクル、日本のクラウド・コンピューティングとAIに80億ドル超を投資へ
オラクルは、日本のクラウドコンピューティングとAIインフラストラクチャの拡張のために、今後10年間で80億ドル以上を投資する計画を発表しました。この投資により、Oracle Cloud Infrastructure (OCI) の事業が日本国内で拡大されることを目指しています。オラクルは、顧客とパートナー企業が日本のデジタル主権要件に対応できるように、日本を拠点とするサポートと運用チームを強化します。東京と大阪にあるパブリッククラウドのリージョンを含む、国内のカスタマーサポートと運用チームが増強される予定です。OCI Dedicated Regionは顧客が自社のデータセンターでオラクルの全てのクラウドサービスを実行できるようにし、Oracle Alloyはパートナー企業がOCIのクラウドサービスを再販し、カスタマイズすることを可能にします。
経産省、AI・クラウド開発の国内企業に725億円の助成
経済産業省は、AIとクラウドサービスの開発を支援するため、国内企業5件に最大725億円の助成を行うと発表しました。この助成は、「経済安全保障推進法」に基づいて行われ、国内の重要情報を管理するシステムや開発体制の自立を促すことを目的としています。国内企業に対する依存度が高い現状を踏まえ、クラウドサービスの提供を強化し、生成AIなどの技術開発を国内で行う体制を整えることが求められています。特に、生成AIの分野では、サービス供給が制約されると大きな影響が出るため、計算資源を国内に確保し、強靭な開発基盤の構築が重要視されています。今回の助成の主な条件は、「AIに関わる計算資源としてのGPUクラウドサービスの提供」で、最大でさくらインターネットに501億円の助成が行われます。その他にGMOインターネットグループ、RUTILEAとAI福島、KDDI、ハイレゾとハイレゾ香川が助成対象となっています。
ロボット&デバイス
Boston Dynamicsは、新しい全電動版の人型ロボットAtlasを発表

Boston Dynamicsは、新しい全電動版の人型ロボットAtlasを発表しました。新しいAtlasは、以前の油圧式のモデルに代わるもので、より強力で、動作範囲が広い特性を持っています。このロボットは、製造業の現場でのテストを含めた実用的な応用に向けた開発が進められています。特にHyundaiとの協力のもと、次世代の自動車製造能力の構築に役立つことが期待されています。Atlasの商業展開は、四足歩行ロボットSpotや商用物流ロボットStretchといった以前の製品で培った経験を生かし、少数の革新的な顧客と協力しながら進められます。さらに、Boston Dynamicsは、ロボットの運用に必要なITインフラストラクチャーや安全基準、ワークフローなどを含むデジタル変革エコシステムの構築にも取り組んでいます。また、Orbit™という新しいソフトウェアも導入されており、これによりロボットフリート全体の管理が可能になります。このソフトウェアは現在Spotで利用可能で、将来的にはStretchやAtlasにも統合される予定です。
LLMを用いて、シミュレーション-リアル転移を自動化・高速化する手法「DrEureka」

ロボット技術においては、シミュレーション上で学習したポリシーをリアルワールドに適用する手法が注目されています。しかし、従来のシミュレーション-リアル間転移手法は、報酬関数やシミュレーションパラメーターの手動設計と調整が必要であり、時間と労力がかかる課題がありました。
本研究では、大規模言語モデル(LLM)を用いて、シミュレーション-リアル転移を自動化・高速化する手法「ドクターユーレカ」を提案しています。ドクターユーレカは、タスクのシミュレーションコードと安全性の指示のみを入力として受け取り、適切な報酬関数と領域ランダム化(DR)パラメーターを自動生成します。
実験では、ドクターユーレカが既存の人手設計の手法と同等以上の性能を示すことを確認しました。さらに、ヨガボール上を歩行するなどの新規ロボットタスクにも適用可能であることを示しました。
ドクターユーレカのコンポーネントは以下の通りです:
1. ユーレカによる報酬関数の生成
2. 報酬値を考慮したシミュレーション物理パラメーターの推定
3. LLMによるDRパラメーターの自動生成
4. 生成された報酬関数とDRパラメーターを用いてポリシーの学習
定量的な実験結果に加え、ヨガボール上の歩行など実世界タスクでのドクターユーレカの頑健性も確認しました。さらに、安全性指示の導入やシミュレーション物理パラメーターの事前推定の重要性なども示しています。
今後の課題として、実世界の失敗事例をフィードバックとして活用し、LLMによる反復的な最適化を行うことが考えられます。また、視覚センサーなどの活用によるポリシーの性能向上も期待できます。
日常会話を録音して要約できるペンダント型AIガジェット「Pendant」

Limitlessはオンライン会議向けのAIツールで、会話内容の文字起こしや要約が可能です。ツールはWindows、macOS、ウェブアプリに対応しており、ZoomやSlackなど多様なオンライン会議ツールと連携可能です。画面は「Prep」(会議の前提情報表示)、「Transcript」(リアルタイム文字起こし)、「Notes」(内容の文脈ごとのまとめ)、「Summary」(会議要約)の4つに分かれています。無料プランでは月10時間まで、有料プランでは無制限にAI機能を利用でき、有料プランは月額19ドルです。
また、Pendantは、日常会話を録音してLimitlessに送信し、要約できるペンダント型デバイスです。カラーバリエーションは8種類あり、内部には100時間稼働のバッテリーが内蔵されています。幅は31.9mm、厚さは16mmで、ストラップを使用して首にかけるか、襟元に直接挟んで固定することができます。価格は99ドルで、2024年第4四半期に出荷が開始される予定です。


コメント