
注目の新サービス
ChatGPT新プラン「Team」月額30ドル/人
★管理者コンソールがあるよ
★チーム用の専用のワークスペースがつくれるよ
★ChatGPTのバージョン管理ができるよ
- https://openai.com/chatgpt/team
- ChatGPT Plus の上位互換? 新しく発表されたTeam Plan について解説
- GPT-4 with 32k context: 32,000トークンのコンテキストは、通常のモデルよりもはるかに多くの情報を含むことができ、複雑なタスクや詳細なドキュメント作成に有用です。
- DALL·E 3: 最新のDALL·E 3モデルは、高度な画像生成能力を持っています。Advanced Data Analysis: この機能は、大量のデータを解析し、洞察を提供するのに役立ちます。
- Browsing: ブラウジング機能を利用可能
- Customized GPTs: 独自のニーズに合わせてGPTモデルをカスタマイズすることができます。
- Security & Privacy: Team Planでは、ビジネスデータや会話内容を保護するための高度なセキュリティとプライバシー保護措置が提供されます。これには、管理者コンソールや専用のワークスペースが含まれます。また、ユーザーのビジネスデータや会話をトレーニングデータとして使用しないという方針があります。
- さらに、特定の目的のためにカスタマイズされたChatGPTのバージョン、GPTsの作成とチーム内限定公開が可能です。
OpenAI、「GPT Store」開始
★自分の作ったGPTsを公開できるよ
★2024年中に収益化も可能になるよ
★「GPTs開発の教科書」は参考になるよ
- https://openai.com/blog/introducing-the-gpt-store
- GPT Store導入: ChatGPT Plus、Team、Enterpriseユーザー向けに開始。
- 利用者の成果: 既に3百万以上のカスタムChatGPTがユーザーによって作成されている。
- 週ごとの新しいGPT: 役立つGPTを定期的に特集。
- GPTのストアへの追加方法: GPTの保存とビルダープロファイルの検証が必要。
- ビルダーの収益化: 2024年第1四半期にビルダーの収益プログラムを開始予定。
- TeamとEnterpriseのカスタマイズ: チームサイズに応じたTeamプラン、Enterprise顧客向けには管理機能を強化したGPT Storeの提供。
- プライバシー保護: ChatGPT TeamおよびEnterpriseでは、会話内容をモデル改善に使用しない。
- 探索方法: chat.openai.com/gptsでGPTを探索可能。
- GPTs開発の教科書
とくに注目のニュースをピックアップ!
LangChainの安定版リリース
★LangChainの初の安定版が出たよ
★これで安心して使えるね
★v0.2.xの計画も進んでいるよ
- https://blog.langchain.dev/langchain-v0-1-0/
- LangChain v0.1.0について
- LangChain v0.1.0は、LLM(Large Language Model)アプリケーション開発用のフレームワークの最初の安定版です。PythonとJavaScriptの両方で利用可能で、主な特徴としては以下のような点が挙げられます:
- アーキテクチャの変更:langchain-coreとパートナーパッケージを分離し、より整理されたプロジェクト構造。
- バージョニングの標準化:公開APIに対する破壊的変更はマイナーバージョンの変更を、バグ修正や新機能はパッチバージョンの変更を伴う。
- 第三者統合:700近くの異なるLLM、ベクトルストア、エージェントツールとの統合。
- 観測性:システム内の詳細なアクティビティを可視化するためのLangSmithツール。
- コンポーザビリティ:LangChain Expression Language(LCEL)を使用して、より高度なカスタムチェーンを作成。
- ストリーミング:LLMの応答または中間ステップをリアルタイムでストリーミング。
- 出力パーシング:LLMからの構造化された応答を取得するためのOpenAI Function callingサポート。
- リトリーバル:プライベートデータとLLMの組み合わせを容易にするための高度な検索戦略。
- エージェント:ツール使用と推論のサポートを通じてLLMによるアクションの有効化。
EAとe/acc
★EA(効果的利他主義):AIは危険!
★e/acc(効果的加速主義):技術はすべてを解決する!OpenAIのサム・アルトマンはe/accだよ
- OpenAI内紛劇の背後に「21世紀の優生思想」、EAコミュニティとe/accの危険性
- EA(効果的利他主義)
- EAは「効果的な利他主義」の略称で、2011年に英オックスフォード大学の大学院生ウィリアム・クラウチ(後のウィリアム・マッカスキル)によって創設された。マッカスキルは28歳で世界最年少の哲学科准教授となった。
- EAコミュニティは、高収入職業に就いて収入の一部(10%以上)を寄付することを「効果的」と捉える。
- EAは「長期主義」の考え方に基づき、高度なAIが人類の生存を脅かす可能性を懸念。
- 最近、EAはサム・バンクマン=フリードの逮捕と有罪判決により評判を落とした。EAコミュニティは白人男性優位であり、カルト的な文化を持つとの告発もある。
- e/acc(効果的加速主義)https://www.theheadline.jp/articles/972
- e/accは「効果的な加速主義(Effective Accelerationism)」の略称で、2022年に作られたネットミーム。EA(効果的な利他主義)のパロディとして作成された。命名者は「ベフ・ジェゾス」という匿名のネット人格で、Amazon創業者ジェフ・ベゾスのパロディ。
- テクノロジー業界で広まっているマインドセットであり、テクノロジーの進歩と資本主義の推進を通じて社会改革を目指す考え方。
- 加速主義の考え方を唱え、資本主義を極めて技術的特異点(シンギュラリティ)に到達することを目指す。
- 現実世界のコミュニティや社会運動ではなく、ネット上のミームであるが、テクノロジー業界の投資家や起業家に支持されている。
- マーク・アンドリーセンやサム・アルトマンなど著名なベンチャー投資家が支持を表明している。
AIと法律・規制~世界の動き
★世界的に生成AIを規制しようという流れがあるよ
★区別のためにコンテンツに来歴情報を付与するのは大事だよ
★これからどうなっていくか注目だよ
- ニューヨークタイムズ、記事流用で数千億円被害が出たとして、OpenAIとMicrosoftを提訴
- 生成AIが作成する文章はNYTの記事を繰り返し要約していて、著作権の侵害にあたると主張。記事利用に対する「公正な対価」を要求。
- 生成AIのコンテンツ来歴証明技術開発団体「CAI」と「C2PA」
- C2PA(Coalition for Content Provenance and Authenticity)
- デジタルコンテンツの来歴(作成者、作成日時、加工歴など)を証明する技術仕様を策定する団体。
- 暗号技術を用いてデジタルコンテンツに来歴情報を付与する。
- 主要参加企業:Adobe、BBC、Intel、Microsoft、Amazon (AWS)、Sony、Canon、NHK、Nikon など。
- デジタルコンテンツの作成、編集、配信、メディアなどの幅広い企業が参画。
- CAI(Content Authenticity Initiative)
- デジタルコンテンツの信憑性・出所に関する標準仕様の利活用を推進する団体。
- 実質的にはC2PAの技術仕様を利用。
- 参加企業にはAFP通信社、AP通信、Reuters、Getty Images、NVIDIA、Qualcommなどが含まれる。
- C2PAと重複する部分も多いが、メディア系企業と半導体メーカーが多く参加。
- C2PA(Coalition for Content Provenance and Authenticity)
- 英最高裁、AI考案発明品の特許登録を認めず
- アメリカで、AIモデルのトレーニングデータ開示義務化法案が提出される(AI財団モデル透明法)
AIと法律・規制〜日本の動き
★日本でもAIを規制しようという流れがあるよ
★とくに著作権との関係が議論されているよ
★まだ素案だけどこれからどうなるか注目だよ
- 文化庁の「AIと著作権に関する考え方について」
- 「AIと著作権に関する考え方について(素案)」の速報解説① 、「AIと著作権に関する考え方について(素案)」の速報解説②
- アイデアと表現の区別:LoRAを意識した見解。著作権法は表現を保護するが、アイデアは保護しない。アイデアが類似する生成物の大量生成は、著作権者の利益を不当に害するとは見なされない。しかし、作品群が共通の作風や画風を持つ場合、これらは表現として評価され得るため、保護の対象となる可能性がある。
- 情報解析用データベースの利用:情報解析に活用可能な形で整理されたデータベースの著作物が販売されている場合、このデータベースを複製する行為は、著作権者の利益を不当に害すると考えられる。
- 学習を防止する技術的措置:AI学習のための著作物複製を防止する技術的措置(例: robots.txtの利用、認証システム)がある場合、これらの措置を回避して行う複製は、著作権者の潜在的な販路を阻害するとして不当と見なされる。
- 海賊版の利用とその責任:海賊版を含む権利侵害複製物をAI学習に使用する行為は、新たな著作権侵害を助長する可能性があり、開発者や提供事業者に責任が生じる可能性が高い。
- 著作権侵害の有無の考え方:AI利用者が既存の著作物を認識しており、これと類似したものをAIで生成した場合、依拠性が認められ、著作権侵害が成立する。AI利用者が既存の著作物を認識していない場合でも、AIがその著作物を学習していた場合は通常、依拠性が認められ、著作権侵害になり得る。
- 侵害に対する措置:生成AIを利用して侵害をした者に対しては、新たな侵害物の生成や既に生成された侵害物の利用に対する差止請求、廃棄請求が可能。生成AIの開発事業者に対しては、データセットからの廃棄請求や生成AIに技術的な制限を付す方法が考慮される。
- 侵害行為の責任主体:生成AIの開発事業者やサービス提供事業者も、侵害物が高頻度で生成される場合や、類似物の生成を抑止する技術的手段を施していない場合、責任を負う可能性が高まる。
- 生成物の著作物性:AI生成物の著作物性は、プロンプトの分量・内容、生成の試行回数、複数の生成物からの選択、生成後の加筆・修正などを総合的に考慮して判断される。
富士通の会計システムの欠陥英で裁判中
★富士通のシステムの欠陥のせいで英国最大の 冤罪事件が起きてしまったよ
★富士通の欧州支部長がイギリス議会に呼ばれたよ
- 富士通の会計システム欠陥による英大規模冤罪
- スナク英首相が、富士通の会計ソフト「ホライゾン」に関連した冤罪事件で、被害者に補償を提供する法案を提出することを発表。
- 1999年から2015年にかけて、736人の郵便局長が富士通の会計ソフトの欠陥により横領の疑いで訴追された。
- この事件は英国史上最大規模の冤罪事件とされている。
- 2019年に郵便局長ら555人が起こした集団訴訟により、英政府が約1億2000万ポンドの補償金を支払った。新法案では、被害者一人あたり7万5000ポンドの補償金を支払う予定。
- 下院のビジネス貿易特別委員会が富士通幹部に対して証言を要請。英国内では富士通に対する批判が再燃しており、政府調達からの排除を求める声も出ている。
- 富士通は下院の証言に応じ、「調査に全面的に協力する」とコメントしている。
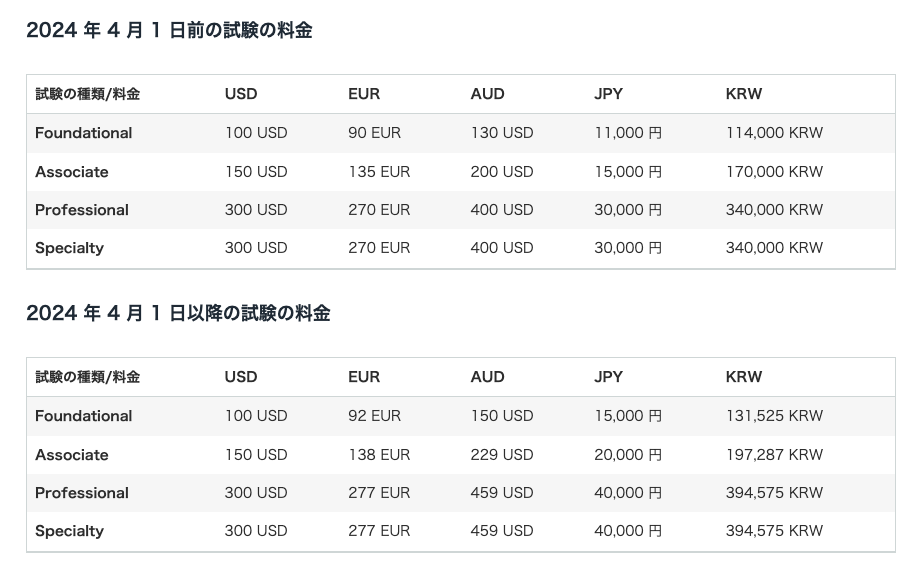
AWS認定試験の値上げ
★AWS認定試験が値上がりするよ
★2024年4/1からだよ 値上がりする前に受けよう!
- 米AWSが提供するAWS認定試験の料金が4月1日から値上がりする。
- 4,000円~10,000円の値上がり
- https://aws.amazon.com/jp/certification/policies/before-testing/
とくに注目の技術をピックアップ!
LoRA
★LoRAはLLMと画像生成で、効率と速度を向上させる技術だよ
★画像を追加学習してチューニングすると、特定のキャラクターや画風を再現できるよ
★追加学習済みのモデル(通称LoRAファイル)を使うと、自分で学習しなくても画風がつかえるよ
- LLMチューニング手法「LoRA」のポイントと活用例
- LoRA: Low-Rank Adaptation of Large Language Models
- LoRAの基本概念: LoRAは、大規模なニューラルネットワークモデルの微調整に使用される技術。特に、トランスフォーマーベースの言語モデルに適用される。この技術は、ニューラルネットワークの密な層に低ランクのパラメータ化された更新行列を導入し、モデルの一部の重みのみを更新する。これにより、トレーニングに必要なパラメータの数を削減し、効率的にモデルを微調整できる。
- LLMでの応用: LoRAは、事前訓練された言語モデルに適用され、特定のタスクへの効率的な適応を可能にする。これは特にトランスフォーマー言語モデルで有用であり、モデルの大部分を変更せずに特定の重みを修正する。このアプローチにより、メモリとストレージの使用量を削減し、GPUを少なくしてのトレーニングが可能になる。
- LCM-LoRA: Real-Time Image Generation Neural Network
- 画像生成への応用: LCM-LoRA(Latent Consistency Model – Low-Rank Adaptation)は、テキスト記述やスケッチからリアルタイムに画像を生成する革新的な技術で、画像生成プロセスの効率と速度を大幅に向上させる。LCM-LoRAは、画像生成のために必要なサンプリングステップ(元のテキストや画像を詳細で高品質な画像に変換するプロセス)の数を削減する。また、この方法は2次元だけでなく3次元のシーンの生成にも応用可能。現在Stable Diffusionでテストされているが、他のテキストから画像へのモデルにも統合する可能性がある。
- 追加学習への応用: 特定の画像(数十枚ほど)を追加学習させ、元のモデルをチューニングすることで特定のキャラクターや画風を再現できる。
- https://civitai.com/models
- Stable Diffusionに関するモデルやプロンプトが共有できるサイト
日本語特化LLM「Swallow」「Karasu・Qarasu」
★東工大・産総研が日本語対応LLM「Swallow」を出したよ
★Swallowは日本語に関して最高性能のモデルだよ
★LightBlue社も日本語対応のLLMを出したよ
★SwallowはLlama2ベース、KarasuはShisaベース、QarasuはQwen-14Bがベースだよ
- 東京工業大学と産総研の日本語特化LLM「Swallow」 、東工大と産総研、日本語対応の言語モデル「Swallow」無償公開
- 大規模言語モデルSwallowは、東京工業大学情報理工学院の岡崎研究室、横田研究室、国立研究開発法人産業技術総合研究所の研究チームによって開発された。
- Swallowは、英語の言語理解と対話の能力を持つ大規模言語モデルLlama 2の日本語能力を向上させるために、日本語の語彙を追加し、日本語データを使用して継続的な事前学習を行った。
- Swallowは、2023年12月現在、日本語に関して最高性能の大規模言語モデルであり、7B、13B、70Bのモデルが提供されている。
- Lightblue、商用日本語LLM「Karasu」「Qarasu」の公開
- Karasuシリーズは、70億パラメータのShisaモデルに対して、日本語と英語の学習データを使用して70億トークンで継続事前学習とファインチューニングを実施したモデルである。 13Bの一部のモデルと同等の性能を持ちつつ非常に軽量である。
- Qarasuシリーズは、140億パラメータのQwen-14Bモデルをベースにし、Karasuシリーズで得た経験を活かしてファインチューニングを行ったモデルである。既存の日本語公開モデルの中で最高性能を示し、gpt-3.5に匹敵する性能を持っている。
- 日本語言語モデルの性能評価に用いられるMT-Benchの6つのタスクの平均スコアでは、Karasuが6.70、Qarasuが7.60を記録している。
- モデル名の由来は、日本神話に登場するカラスであり、導きの神の「八咫烏(ヤタガラス)」に由来している。
AppleのAI開発
★AppleもAI開発に本腰を入れてるよ
★フラッシュメモリを活用してLLMを効率的に実行する方法を研究しているよ
★将来的にはスマホでLLMを動かしたいのかも?
★マルチモーダルLLM「Ferret」も開発しているよ
- Apple、LLMの外部フラッシュメモリ保存技術
- LLM(Large Language Models)は高性能ですが、計算能力とメモリが必要で、メモリ容量が制限されているデバイスでの運用が難しい。
- 現在の方法では、モデル全体をDRAMにロードする必要があり、DRAMの制限によりモデルサイズが制約される。
- Appleの研究者は、メモリ制限のある環境でもフラッシュメモリを活用してLLMを効率的に実行する新しい方法を研究中。
- フラッシュメモリの読み込み速度は遅いが、大きなデータブロックを一度に読み込むことで速度が向上する特性を活用するアイデアが研究の一部。
- Ferret: Refer and Ground Anything Anywhere at Any Granularity
- 米アップル、既存のMLLMよりも20.4%高い性能「Ferret」を開発
- 「Ferret」は新しいMultimodal Large Language Model(MLLM)で、画像内の任意の形状や細部を正確に理解し、画像内の何かに言葉を関連付け、その物体や要素を特定の語句やフレーズで表現できる。
- Ferretの能力を向上させるために、GRITと呼ばれる包括的な指示チューニングデータセットを作成しました。このデータセットには、豊富な階層的な空間的知識を含む110万のサンプルが含まれており、モデルの頑健性を向上させるために95,000の難しいネガティブデータも含まれています。
- AppleはAIのトレーニングに「1日あたり数億円」を費やしていると報じられる
- Appleのティム・クックCEOが独自の生成AIを開発中であると認める、Appleの研究開発費は前年同期より約4400億円も増加
- Appleはすでに社内で業務に独自のチャットAI「Apple GPT」を活用している
LLMの自己学習・自己対戦
★人間の作ったテキストではなく、LLMが生成したテキストで自己学習する方が性能向上 する可能性があるよ
★AlphaGoも自己学習したほうが性能がよかったよ
- 自分の過去と対戦することでLLMの性能を向上させる手法「SPIN」
- LLM(Large Language Model)の実用性を向上させるためには、現在は人間による注釈付きデータに依存しており、ファインチューニングという手法がよく使用されている。
- 人間の注釈データに依存するのは効率的ではなく、LLMが自身で強化できる方法が求められている。
- 研究者らは、LLMが自己学習し、追加のトレーニングデータや人間のフィードバックを必要としない方法を模索しており、このアプローチの一環としてセルフプレイを提案している。
- セルフプレイは、LLM自身が過去の自身との対戦結果をもとにファインチューニングを行い、自己学習を進めるアプローチであり、これによりモデルの性能向上が期待されている。
- また、セルフプレイの他にも、Self-play(自己対戦)、LLMの合成データ、カリキュラム学習など、先行研究からインスピレーションを得た手法が検討されている。
- LLMによる自己学習の有効性検証
- 既存の言語モデルは人間生成データに依存しており、データ収集やファインチューニングに課題がある。
- 人間生成データへの依存性を減らし、言語モデルの問題解決能力を向上させるため、自己学習の新しいアプローチが模索されている。
- 自己学習アプローチは、モデルが自身でデータを生成し、それを評価する方法で、期待値最大化に基づく強化学習の一形態である。
- このアプローチは、数学的推論やコード生成などのタスクに適用され、モデルの性能向上が確認されている。
- 研究は従来の人間生成データに依存するファインチューニングと比較して、自己学習によって大幅な性能向上が実現されることを示しており、広範囲の問題解決タスクに適用可能であることが示唆されている。
merge kit
★merge kitは2つ以上のLLMをマージできるツールだよ
★GPUは使わなくていいよ
★4種類のマージのしかたが選べるよ
- Merge Large Language Models with mergekit
- モデルマージングは、2つ以上のLLM(大規模言語モデル)を1つのモデルに組み合わせる技術です。これは新しいモデルを作成するための比較的新しく実験的な方法で、GPUは必要ありません。モデルマージングは驚くほどうまく機能し、Open LLM Leaderboardで多くの最先端のモデルを生み出しています。
- 現在mergekitで実装されているのは4つのマージ方法です。
- SLERP(球面線形補間)は、2つのベクトル間を滑らかに補間する方法で、変化率を一定に保ち、ベクトルが存在する球面空間の幾何学的特性を保持します。SLERPは現在最も一般的なマージング方法であり、2つのモデルの組み合わせに限定されていますが、Mistral-7B-Merge-14-v0.1.2など、複数のモデルを階層的に組み合わせることも可能です。
- TIES(Task Interaction via Efficient Subspace-Merging)は、複数のタスク専用モデルを効率的に1つのマルチタスクモデルにマージするための方法です。
- DARE(Data Augmentation for Robustness Enhancement)は、TIESと似たアプローチを使用しますが、プルーニングとリスケーリングという2つの主要な違いがあります。
- Passthroughメソッドは、他の方法とは大きく異なります。異なるLLMからのレイヤーを連結することで、異常な数のパラメータを持つモデル(例:2つの7Bパラメータモデルを使用した9Bモデル)を生成できます。このテクニックは非常に実験的ですが、goliath-120b(2つのLlama 2 70Bモデルを使用)などの印象的なモデルを作成することに成功しました。最近リリースされたSOLAR-10.7B-v1.0も、論文で「depth-up scaling」と呼ばれる同じアイデアを使用しています。
vLLM
★vLLMはメモリ効率を高めて、LLMの出力スピードをアップするライブラリだよ
★Hugging FaceのTransformersみたいなやつだよ
- https://github.com/vllm-project/vllm
- LLMの高速推論のライブラリ「vLLM」
- 大規模言語モデルの出力スピードを最大24倍に高めるライブラリ「vLLM」が登場、メモリ効率を高める新たな仕組み「PagedAttention」とは?
- vLLMは大規模言語モデル(LLM)を操作するためのライブラリの一部で、Hugging FaceのTransformers(HF)やText Generation Inference(TGI)と同様のものです。
- vLLMは、処理速度の向上に優れており、NVIDIA A100 40GBおよびNVIDIA A10G上で高速な推論を実現しています。特にvLLMは、Transformersに比べて24倍の処理速度向上を達成し、TGIに比べても2.5倍の速さです。
- この処理速度の向上は、大規模言語モデルのパフォーマンス調査の結果、メモリがボトルネックであることが判明したためです。大規模言語モデルでは、テキスト生成時にすべての入力トークンからアテンションのキーと値のテンソルを計算し、GPUメモリに保存するが、これには以下の問題がありました:
- メモリ占有が大きく、LLaMAの13Bモデルでは1回の処理に1.7GBもメモリを占有。
- KVキャッシュのサイズが動的に変化し、メモリの効率的な管理が難しい。
- そこで、PagedAttentionと呼ばれる仕組みが開発されました。PagedAttentionでは、各入力トークンを一定の長さごとに分割し、連続するKVキャッシュを不連続なメモリ空間に保存可能にし、メモリ効率を大幅に向上させました。
- vLLMを使用することで、GPUの必要数が50%削減され、毎日3万件からピーク時で6万件のリクエストを問題なく処理できるなど、高い安定性が実証されています。
PowerInfer
★PowerInferはGPTとCPUを効率的につかうシステムだよ
★高性能なGPUが不要になるよ
★特定の活性化関数しか使えないよ
- 消費者向けGPUでLLMを動かす「PowerInfer」
- PowerInferをとりあえず試す
- 大規模言語モデル(LLM)を運用する上での主要な課題は、高性能なGPUが必要であり、その高価さが研究者や開発者にとって負担となっていること。
- 研究者らは、CPU-GPUハイブリッドの手法を採用し、消費者向けGPUとCPUを効率的に使用するシステムであるPowerInferを開発した。
- PowerInferのポイントは、メモリ使用量の削減、GPUとCPUのハイブリッド実行、特定の活性化関数(ReLUやReGLU)を使用するモデルでのみ動作すること。
- メモリ使用量の削減は、GPUとCPUにニューロンを適切に割り当てることで実現され、全体的な推論速度向上に寄与する。
- GPUとCPUのハイブリッド実行は、アーキテクチャが工夫されており、推論性能を最大化するために長所を組み合わせて利用する。
- PowerInferは特定の活性化関数を使用するモデルで動作し、現在はReLUやReGLUをサポートしている。
ロボット開発
★模倣学習とはロボットに人間の動きを真似させることだよ
★Google DeepMindはロボット研究をしているよ
★テスラのOptimusは人型ロボットだよ
★ロボット開発が進むと人間の生活は大きく変わるよ
- 卵を割り服を畳める2本腕ロボット「Mobile ALOHA」開発
- 低コスト全身テレオペレーションシステム「Mobile ALOHA」は、車輪付きの本体と前方の2本のアームで構成されている。オペレーターはロボットの背後から2本のアームを操作してタスクを教える。
- ロボットは本体部分の動きと腕の動作を連結して模倣学習を行い、強力な性能を実現。
- ロボットは複雑な長時間のタスクを実行可能。例えば、ワイングラスの持ち上げ、エビの両面ソテー、卵の割り、服の畳み、ラップのかけ、スマートフォンへの充電器の差し込みなどの細かな作業が可能。
- Google DeepMindのロボット研究「AutoRT」「SARA-RT」「RT-Trajectory」
- AutoRT:大規模基礎モデルを利用してロボットの実践的な訓練データを収集。複数のロボットを同時に指示し、様々な環境でのトレーニングデータを収集。
- SARA-RT:Robotics Transformer (RT)モデルをより効率的なバージョンに変換するシステム。「up-training」というモデルファインチューニング方法を利用。
- RT-Trajectory:ロボットが物理的な動作を理解し実行する方法を改善するための、トレーニングビデオにロボットの動きを示す視覚的な輪郭を自動的に追加するモデル。
- 新型テスラ人型ロボット「Optimus」
- 新型の二足歩行ロボットで、指に触覚センサーを搭載。
- 卵をつまみ、割らずに他の場所に移し替えることが可能。
通信衛星技術 Starlink vs Kuiper
★イーロン・マスクのStarlinkが有名だけど、Amazonも通信衛星プロジェクト「Kuiper」を進めているよ
★Kuiperの衛星は打ち上げに成功しているよ
★Starlinkはauスマホと直接通信できるようにするよ
- スペースX、スマホとの直接通信衛星
- KDDIは2023年8月30日に、Space Exploration Technologies Corp.(スペースX、CEO: イーロン・マスク)と業務提携を発表。
- この提携により、Starlinkの最新鋭の衛星とauスマートフォンとの直接通信サービス(本サービス)の提供を計画。
- StarlinkとKDDIのau通信網を組み合わせることで、auスマートフォンが衛星と直接接続し、空が見える場所であれば圏外エリアでも通信可能に。
- 本サービスは2024年内の提供開始を予定しており、最初はSMSなどのメッセージ送受信から開始、その後音声通話やデータ通信も対応予定。
- Amazonの衛星通信「カイパー」、100Gbpsの光衛星間通信に成功
- Amazonの「Project Kuiper」は、低軌道衛星通信システムで、100Gbpsの光衛星間リンク(OISL)テストに成功。
- プロトタイプ衛星「KuiperSat-1」と「KuiperSat-2」を使用し、約1000kmの距離で100Gbpsリンクを維持。
- 2024年前半に量産型衛星の打ち上げ予定、OISLの動作が確認された。
- 2024年後半にサービス開始予定。
AI・分析技術
【DL技術】CNNの軽量化手法「低ランク近似」
【DL技術】Graph Neural Network (GNN)入門
【DL技術】一般的な視覚認識タスク向けの汎用的Transformer「CSWin Transformer」
【DL技術】「CLIP」を用いてfine-tuningなしでセグメンテーション
【DL技術】新しいVision Transformer「Swin Transformer」の実装理解
【DL技術】物体検出・インスタンスセグメンテーションのモデルツールボックス「MMdetection」
——————————
【データ前処理】Pandas vs. Polars: 処理速度と使いやすさ比較
【データ前処理】統合データ処理ライブラリ「Ibis」100本ノック
【AutoML】Autogluonで3行でAutoMLを実行
——————————
【機械学習モデル】ベイズ的方法の決定木: Bayesian CART
【機械学習モデル】Python時系列予測ライブラリの比較
——————————
【分析技術】ZOZO推薦基盤チームの2023年振り返り
【分析技術】Group-Hot Encodingの活用法
【分析技術】PyTorchとPythonのバージョン更新手順
【分析技術】sklearnの「SimpleImputer」で欠損値を補完する
生成AI
【生成AI技術】LoRAトレーナー「Kohya Trainer」
【生成AI技術】生成AIの仕組みの掴み方
——————————
【画像生成AI】高速画像生成AI「StreamDiffusion」
【画像生成AI】Googleの画像生成AI「Imagen 2」リリース
【画像生成AI】Getty ImagesとNVIDIAの画像生成AIサービス開始
——————————
【音声・音楽生成AI】音声変換もできる音楽生成AI「Amphion」
【音声・音楽生成AI】テキストから歌生成「Suno AI」使用法
【音声・音楽生成AI】テキスト・画像・動画からの音楽生成「M2UGen」
——————————
【動画生成AI】動画生成AI「Stable Video Diffusion」解説
【動画生成AI】テキストから動画生成「W.A.L.T」モデル
【動画生成AI】Googleの新マルチモーダルAI動画生成ツール「VideoPoet」
【動画生成AI】「Stable Zero123」で作った3Dモデルを「Mixamo」でアニメーション化する
【動画生成AI】テキスト・画像から動画を生成する「DragNUWA」
——————————
【その他生成AI】音楽生成AI「Suno」と「StemGen」着せ替えAI「Outfit Anyone」など
【その他生成AI】画像キャプション生成AI「BLIP-2」
新しいLLM
【新しいLLM】Googleの医療特化言語モデル「MedLM」
【新しいLLM】JPモルガン、請求書、領収書などに特化したLLM「DocLLM」開発
【新しいLLM】マルチモーダルLLM「Unified-IO 2」
【新しいLLM】Mixtral 8x7B: 無料で商用利用可能な、低推論コストで高性能モデル
【新しいLLM】Microsoftの小規模言語モデル「Phi-2」
【新しいLLM】Microsoftの小規模言語モデル「Orca」の解説
【新しいLLM】東京工業大学と産総研の日本語特化LLM「Swallow」 、東工大と産総研、日本語対応の言語モデル「Swallow」無償公開
【新しいLLM】Lightblue、商用日本語LLM「Karasu」「Qarasu」の公開
【新しいLLM】日本語LLM「ELYZA-japanese-Llama-2-13b」の公開
LLM技術
【LLM技術解説】Attention機構とLLMの関係
【LLM技術解説】小規模LLMの限界と改善策
【LLM技術解説】LLMマルチエージェントの概観
【LLM技術解説】LLMトレーニングの「分散学習」
——————————
【LLM新技術】LLMの新しいアライメント(AIを人間の倫理に合わせる)手法「URIAL」
【LLM新技術】言語データ無しで大規模ビジョンモデル (LVM)構築
【LLM新技術】Google、LLMと幻覚を防止する「評価器」を組み合わせたAIシステム「FunSearch」を開発
【LLM新技術】プロンプト高度圧縮技術「LLMLingua」
【LLM新技術】LLMによる自己学習の有効性検証
【LLM新技術】Apple、LLMの外部フラッシュメモリ保存技術
【LLM新技術】日本語LLMのPPO(ポリシー最適化)ファインチューニング
【LLM新技術】LLMのハルシネーションを検証するアプローチ「LLMファクトスコープ」
【LLM新技術】人間の教材に基づくチューニングでLLMを賢くする
【LLM新技術】自分の過去と対戦することでLLMの性能を向上させる手法「SPIN」
【LLM新技術】LLMパラメータ数とGPUメモリの分析
【LLM新技術】LLMの知識を直接編集して効果的に最適化する手法「Knowledge Editing」
——————————
【LLMのツール】複数のLLMモデルを一つにマージするツール「mergekit」の解説
【LLMのツール】HuggingFaceより高速なfine-tuning用ライブラリ「Unsloth」と「TRL」
——————————
【LLMの高速化・効率化】LLMの高速推論のライブラリ「vLLM」
【LLMの高速化・効率化】消費者向けGPUでLLMを動かす「PowerInfer」
【LLMの高速化・効率化】LLMチューニング手法「LoRA」のポイントと活用例
——————————
——————————
【プロンプト】Google開発、表データ特化プロンプトエンジニアリング「Chain of Table」
【プロンプト】プロンプトの原則26ヶ条の報告
——————————
【LangChain】LangChain初の安定版リリース
【LangChain】LangchainでのLLMエージェント作成比較
——————————
【LLMの活用】LLMのテキスト埋め込みのレコメンド活用法
【LLMの活用】情報抽出タスクにおけるLLM活用の網羅的調査
【LLMの活用】LLMを用いた文書要約手法
【LLMの活用】大規模言語モデルのソフトウェア開発応用
【LLMの活用】英語論文のChatGPT-4執筆手順
【LLMの活用】業務システムへのGPT API組込み虎の巻
【LLMの活用】GPTs開発の教科書
——————————
【LLMの評価・比較】LLMの出力評価方法まとめ
【LLMの評価・比較】AGIベンチマーク「MMMU」の成績
【LLMの評価・比較】GeminiとGPT-4Vの画像認識能力比較
IT・AIの活用と未来
【人間とAIの未来】OpenAIのサム・アルトマンCEOの経歴
【人間とAIの未来】AI規制派と効果的加速主義 (e/acc) , AI推進派「e/acc」, OpenAI内紛と「EA vs e/acc」
【人間とAIの未来】OpenAI、AIリスクに関する取締役会拒否権
【人間とAIの未来】OpenAI、 AIが人間の理解を超えた時の制御法の開発進捗
——————————
【AIと法律・規制】生成AIのコンテンツ来歴証明技術開発団体「CAI」と「C2PA」
【AIと法律・規制】OpenAIを提訴するニューヨーク・タイムズ
【AIと法律・規制】英最高裁、AI考案発明品の特許登録を認めず
【AIと法律・規制】アメリカの、AIモデルのトレーニングデータ開示義務化法案
【AIと法律・規制】文化庁「AIと著作権に関する考え方について(素案)」についての考察
【AIと法律・規制】文化庁の「AIと著作権に関する考え方について」
——————————
【日本のTech産業の未来】日本の電子・IT産業の生成AIによる打開策
【日本のTech産業の未来】富士通のハードウェア事業の分離
——————————
【AIの現状と将来の展望】State of AI Report 2023の要点
【AIの現状と将来の展望】デジタル経済 2023年の予測と結果、2024年の予測
ロボット・デバイス
【ロボット】東京大学: GPT-4とロボット連携
【ロボット】非装着VRヘッドセットの動くロボット化
【ロボット】AIで動く自動実験ロボットの開発
【ロボット】Googleのロボット憲法
【ロボット】卵を割り服を畳める2本腕ロボット「Mobile ALOHA」開発
【ロボット】Google DeepMindのロボット研究「AutoRT」「SARA-RT」「RT-Trajectory」
【ロボット】新型テスラ人型ロボット「Optimus」
——————————
【XR】ソニー、コンテンツ制作特化XRヘッドマウントディスプレイ 、ソニーの4K HMD没入型コンテンツ制作システム体験
【XR】空間コンピューティング向けARグラス「XREAL Air 2 Ultra」
——————————
【GPU・AIチップ】 AMDのAIチップ「MI300X」の性能報告
【GPU・AIチップ】NVIDIAの新GPU「RTX 4080 SUPER」シリーズ発表
通信・開発技術
【通信技術】次世代通信網「IOWN」の国際標準化への一歩
【通信技術】日本でWi-Fi 7正式解禁とその影響
【通信技術】スペースX、スマホとの直接通信衛星
【通信技術】能登半島へのスターリンク導入
【通信技術】Googleの高精度レンダリング技術「SMERF」
【通信技術】インターネット高速化技術「L4S」
——————————
【開発技術】iOSで機械学習: CreateMLの使用法
【Web技術】Chrome、サードパーティCookie廃止とその影響
AWS
【AWS】クラスメソッド データアナリティクス通信2024年1月号 機械学習編 AWSデータ分析編
【AWS】AWSの最新情報とトレンドチェック
データ基盤
【Snowflake】2023年12月のSnowflake新機能・変更点まとめ
新技術
【新技術】動く人にモザイクが見える技術の開発
【新技術】他人が装着するイヤフォンへの音楽注入システムの開発
【技術まとめ】主要AIプログラミング支援サービスまとめ
【量子コンピュータ】日米韓の量子コンピューター前進
ニュース
【ニュース】富士通の会計システム欠陥による英大規模冤罪
【ニュース】Gmail迷惑メール対策強化の詳細
【ニュース】AWS認定試験の値上げ情報
【ニュース】Windows 10更新問題とMicrosoftの対策
IT・AIの活用と利用
【IT・AIの活用】Google Cloud Next Tokyoのアーカイブ
【IT・AIの活用】猫の痛み判別AI「CatsMe!」の開発
【IT・AIの活用】Science誌, AIで不正画像チェック
【IT・AIの活用】JR各社の作業ロボットによる保守革命
【IT・AIの活用】自動運転バスの導入検討
つくってみた・やってみた
【つくってみた】AITuberを創る
【つくってみた】ひとりで作ったタスク管理ツールの進化
科学技術
【科学技術】ロングCOVIDとミトコンドリアの関係
【科学技術】JAXAの小型月着陸実証機「SLIM」のライブ配信
【科学技術】家庭用ヘッドセットで脳に電流を流してうつ病を改善
【科学技術】コーヒー豆を挽く前に水で濡らすとおいしくなる
【科学技術】H-IIAロケット打ち上げ成功
その他
【その他】Midjourney CEOデイビッド・ホルツとは何者か
マネジメント・スキルアップ
【マネジメント】チーム中心の組織作りのための6つのチーム設計原則
【マネジメント】テスト実施者の名前を記録しない仕組みづくり
【マネジメント】QAのテストプロセスが自走するチーム体制づくり
【マネジメント】エンジニアリングマネージャー (EM) のセルフ評価解説
【マネジメント】新規プロダクト開発のBadプラクティス
——————————
【スキルアップ】シェルスクリプト完全攻略ガイド
【スキルアップ】英語命名規則の決定版
【スキルアップ】東大松尾研、LLMの講座資料の無料公開
【スキルアップ】2024年版:データエンジニア向け推薦本リスト
【スキルアップ】GitHub資格認定プログラムが一般ユーザに開放
【スキルアップ】Microsoft、初心者向け生成AI学習教材の無償公開
【スキルアップ】西谷流・育児中のエンジニア勉強法
【スキルアップ】おすすめのコマンドラインツール集

コメント