
はじめに
テクノロジー系のニュースをチェックして、「XXXX年XX月のテクノロジーニュースピックアップ!」2023年10月分はこちらをほぼ毎日更新しています。
はじめはリンクとタイトルと見出しだけコピペしていたのですが、続けるうちに欲が出てきて、「用語の意味も調べたいな」「ジャンルでわけたいな」と思うようになり、作業負担も上がっていました。
そして、まとめるところに時間をかけすぎて、実際に記事を読む時間が十分に取れていませんでした。
ということで、Pythonのfeedparserというライブラリを使って、RSSフィードを取得し、csvとして書き出すプログラムを書いてみました。
【2023/10/29追記】
- macにおいて定期実行する方法について、ブログを書きました。macでプログラムを定期実行してみた(launchdを使う)
- URLに対応したタグだけではなく、タイトルからタグ付けを追加するコードを実装しました。テキストファイルに追加タグのリストを記載しておき、それを読み込んでタイトル文字列が一致した場合、タグに加えることにしました。詳細は本記事の最後に記事を書いています。
実装の概要
- feedparserというライブラリを使う。
- RSSのリンクと、そのサイトに対応したタグは、テキストファイルにまとめておき、これを読み込んでRSS feed(指定したサイトの更新)を取得する。
- プログラムを実行した時から30時間以内に更新されたRSS feedを取得する。
- サイトのタグ、更新日時、タイトル、サイトのリンクの情報をデータフレームとする。
- 第一ソートキーとしてタグ、第二ソートキーを更新日時としてソートする。タグは指定した順番で並べたいので、事前にCategorical型に変換して順番をlistで与える。
- スペース区切りのcsvとして出力する。
実装
実行環境はMac, pyenv + poetry + VSCodeです。
環境構築、pyenv, poetryの基本的な使い方については、以前 Macでプログラミングをするための初期設定(pyenv + poetry + VSCode)【2023/10/7更新】にまとめています。
コード
get_rss_feed.py:実行した時間から30時間以内に更新されたRSSのfeedを取得するプログラム。
import feedparser
from datetime import datetime, timedelta
import pytz
import pandas as pd
def get_articles_within_30_hours(rss_url):
# RSSフィードを解析
feed = feedparser.parse(rss_url)
# タイムゾーンの設定
utc = pytz.utc
local_tz = pytz.timezone('Asia/Tokyo') # ここを適切なタイムゾーンに変更してください
# 30時間前の日時を計算(現地のタイムゾーンで)
thirty_hours_ago_local = datetime.now(local_tz) - timedelta(hours=30)
# 30時間以内に更新された記事のみをフィルタリング
recent_articles = []
for entry in feed.entries:
# 公開日時の取得(UTCとして)
published_time = entry.get("published_parsed", entry.get("updated_parsed", None))
if published_time:
published_datetime_utc = utc.localize(datetime(*published_time[:6]))
# 公開日時を現地のタイムゾーンに変換
published_datetime_local = published_datetime_utc.astimezone(local_tz)
if published_datetime_local > thirty_hours_ago_local:
# タイトル、リンク、および更新日時を追加
recent_articles.append((entry.title, entry.link, published_datetime_local.strftime('%Y-%m-%d')))
return recent_articles
if __name__ == "__main__":
# RSSのURLとタグをテキストファイルから読み込む
with open("rss_urls.txt", "r", encoding="utf-8") as file:
rss_data = [line.strip().split(",") for line in file]
# 各RSSのURLから24時間以内の更新を取得して辞書に格納
output_dict = {}
tag_list = []
update_date_list = []
title_list = []
link_list = []
for rss_url,tag in rss_data:
articles = get_articles_within_30_hours(rss_url)
for title, link , update_date in articles:
tag_list.append(tag)
update_date_list.append(update_date)
title_list.append(title)
link_list.append(link)
output_dict['tag'] = tag_list
output_dict['update_date'] = update_date_list
output_dict['title'] = title_list
output_dict['link'] = link_list
# 辞書をデータフレームに変換
df = pd.DataFrame(output_dict)
df['update_date'] = pd.to_datetime(df['update_date'])
# ソートしたい順番のリスト
order = ['【LLM】','【AI・データ分析】','【ITの活用と未来】','【OpenAI】','【Python】','【データ基盤】','【Amazon】','【Java】','【ニュース】','【speakdeck】','【科学技術】','【その他】']
# 'tag'カラムをCategorical型に変更
df['tag'] = pd.Categorical(df['tag'], categories=order, ordered=True)
df.sort_values(by=['tag','update_date'],inplace=True)
# ファイル名を実行時の日付(yyyyMMdd)に設定
filename = "../Desktop/rss_feed/ITNewsPickup" + datetime.now().strftime("%Y%m%d%H%M%S") + ".csv"
df.to_csv(filename,sep=' ', index=False)rss_urls.txt:RSSの取得のためのURLとそのサイトの内容に関係するタグを指定します。
RSS URLの取得方法については後述します。





https://gigazine.net/news/rss_2.0/,【ニュース】
https://www.watch.impress.co.jp/data/rss/1.0/ipw/feed.rdf,【ITの活用と未来】
https://feed.infoq.com/jp,【AI・データ分析】
https://rss.itmedia.co.jp/rss/2.0/news_bursts.xml,【ニュース】
https://ledge.ai/theme/news/feed,【AI・データ分析】
https://qiita.com/tags/llm/feed,【LLM】
https://qiita.com/tags/deeplearning/feed,【AI・データ分析】ターミナルでpython3 get_rss_feed.pyを実行すると次のようなcsvが出力されます。
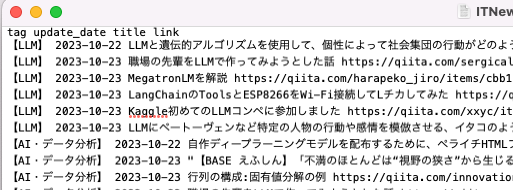
できた〜!
スペース区切りにしているので、ブログで使いやすくなっています。
これでニュースチェックに関わる時間を減らせます!
サイトのHTMLからRSS URLを取得する
RSSのURLは、サイトのURLではなく、HTMLなどから別途取得する必要があります。
Chromeだと、サイトを右クリックして「ページのソースを表示」でサイトのHTMLを表示できます。
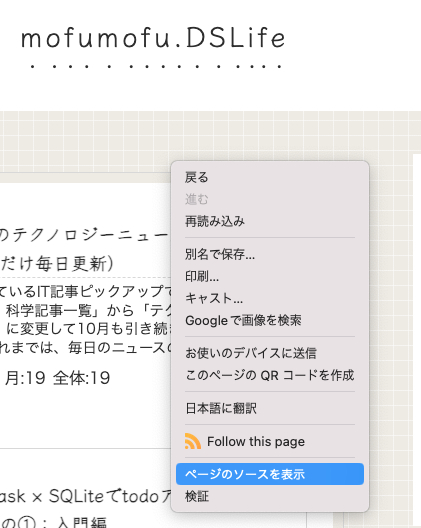
そのサイトのHTMLが表示されます。
「rss+xml」もしくは「atom+xml」に続く”href=”以下のURLがRSSのためのものです。
Ctrl + Fキーを押すと、サイト内検索ができます

たまに、これではRSSのURLを取得できない時があります。ページトップ以外にRSS用のページを持っているサイトもあるみたいです。トップページの下部にRSSへのリンクがある場合はいいのですが、探せない場合もありました…
拡張機能を使ってRSS URLを取得する
そういうサイトについては、今回はChromeの拡張機能「RSS Feed Reader」を使って調べました。
拡張機能をインストールすると、検索窓の隣にマークが出るようになります。そこから拡張機能を使えます。
RSS Feed Readerを選択すると、画面が表示されます。右上の+を押すと、開いているページを購読するためのページに移動します。
いったんサイトをフォローします(本当はフォローしなくてもURLわかるのかな…?)
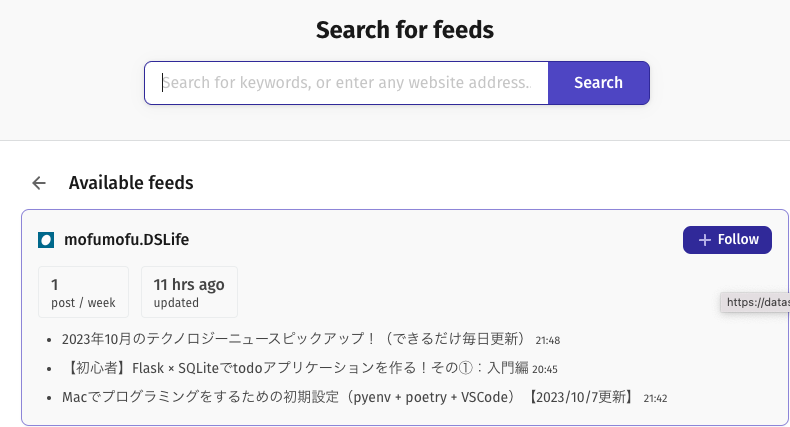
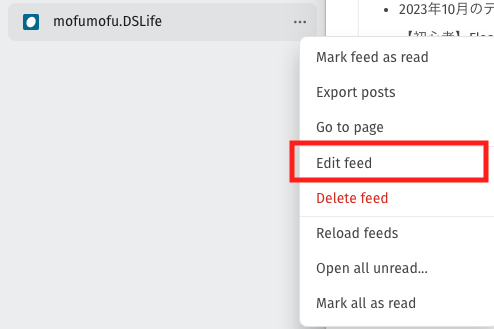
左のバーのなかに先ほどFollowしたサイトが追加されています。ここで…を押して「Edit feed」を選びます。
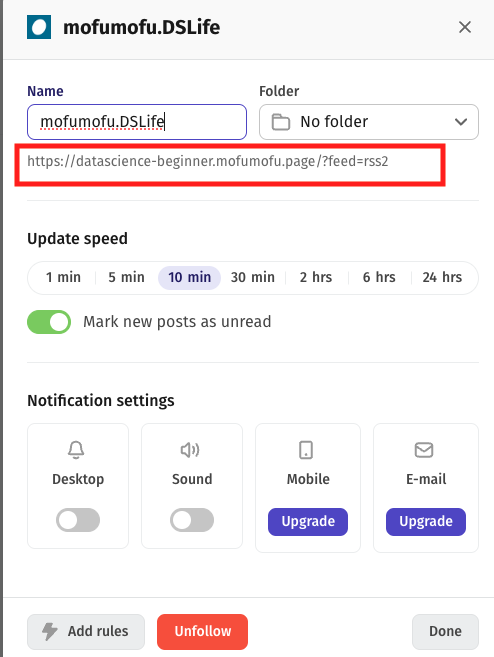
Nameの下に表示されているURLがRSSのものです。
今後の改善ポイント
- タグはサイトごとに与えているが、タイトルから判別できるようにしたい。
- LLMを使えばできるかな?
- お金かけたくないので、オープンソースのLLMを使いたい。
- サイトの内容を読み込んで、要約してもらえたらすごく楽になりそう。
- これもLLMだとできそう。
- RSS URLを取得するのが地味にめんどくさいので、サイトのURLを与えたら自動で探してくれるようにしたい。
- スクレイピングして自動取得できるようにする?
【2023/10/29追記】タイトルからタグを追加する
「改善ポイント」にも書いた通り、LLMや自然言語処理で実装しようかと思ったのですが、結局求めるものとしては「タイトルからタグを生成する」のではなく「タイトル内の文字列の中で、タグにしたい文字列リストに載っている単語があれば、それをタグに追加する」ことだったので、普通に文字列の一致判定で解決しました。でももっとスマートなやり方があるかも…
テキストファイルに追加したいタグの一覧を記載し、それを読み込む形で実装しました。
また、これに伴って複数のタグが付く可能性が生じ、タグのソートをするのが難しくなったので、Categorical変数にするコードはいったん削除しました。いずれ解決したいですね。
あと、地味ですが引数で何時間以内の更新を取得するかを指定できるように修正しました。
import feedparser
from datetime import datetime, timedelta
import pytz
import pandas as pd
import argparse
def get_articles(rss_url, hours):
# RSSフィードを解析
feed = feedparser.parse(rss_url)
# タイムゾーンの設定
utc = pytz.utc
local_tz = pytz.timezone('Asia/Tokyo') # ここを適切なタイムゾーンに変更してください
# hours時間前の日時を計算(現地のタイムゾーンで)
thirty_hours_ago_local = datetime.now(local_tz) - timedelta(hours=hours)
# hours時間以内に更新された記事のみをフィルタリング
recent_articles = []
for entry in feed.entries:
# 公開日時の取得(UTCとして)
published_time = entry.get("published_parsed", entry.get("updated_parsed", None))
if published_time:
published_datetime_utc = utc.localize(datetime(*published_time[:6]))
# 公開日時を現地のタイムゾーンに変換
published_datetime_local = published_datetime_utc.astimezone(local_tz)
if published_datetime_local > thirty_hours_ago_local:
# タイトル、リンク、および更新日時を追加
recent_articles.append((entry.title, entry.link, published_datetime_local.strftime('%Y-%m-%d')))
return recent_articles
if __name__ == "__main__":
# RSSのURLとタグをテキストファイルから読み込む
with open("rss_urls.txt", "r", encoding="utf-8") as file:
rss_data = [line.strip().split(",") for line in file]
# 何時間以内のfeedを読み込むかを実行時引数で指定(デフォルトは26時間)
parser = argparse.ArgumentParser(description='get rss feed.')
parser.add_argument('--hours', default=26, type=int, help='hours')
args = parser.parse_args()
hours = args.hours
article_tags = []
# タイトルから判断するタグリスト
with open('tag_list.txt', 'r', encoding='utf-8') as file:
for line in file:
# 末尾の改行コードを削除してリストに追加
article_tags.append(line.rstrip('\n'))
# 各RSSのURLからhours時間以内の更新を取得して辞書に格納し、データフレームに変換する
output_dict = {}
tag_list = []
update_date_list = []
title_list = []
link_list = []
for rss_url,tag in rss_data:
articles = get_articles(rss_url, hours)
for title, link , update_date in articles:
update_date_list.append(update_date)
title_list.append(title)
link_list.append(link)
article_tag_list = [tag]
for article_tag in article_tags:
# URLに紐づけられたタグ以外でタイトルから判断できるものをタグに追加する
if (article_tag in title) and (article_tag != tag):
tag_appending = f'【{article_tag}】'
article_tag_list.append(tag_appending)
joined_str = ''.join(article_tag_list)
tag_list.append(joined_str)
output_dict['tag'] = tag_list
output_dict['update_date'] = update_date_list
output_dict['title'] = title_list
output_dict['link'] = link_list
df = pd.DataFrame(output_dict)
df['update_date'] = pd.to_datetime(df['update_date'])
df.sort_values(by=['tag','update_date'],inplace=True)
# ファイル名を実行時の日付(yyyyMMdd)に設定
filename = "../Desktop/rss_feed/ITNewsPickup" + datetime.now().strftime("%Y%m%d%H%M%S")
df.to_csv(filename + '.csv',sep=' ', index=False)tag_list.txt
LLM
Microsoft
Apple
Google
dbt
Amazon
Databricks
Docker
RAG
生成AI
LangChain
JavaScript
AWS
Git
Snowflakeおわりに
feedparserライブラリのおかげで、思っていたよりも簡単につくることができました!
これでニュースチェックが格段に楽になりそうです。
使いながらこれから改善していく予定です。LLM実装してみたかったし!楽しみです。


コメント